
L’essor de la datascience, avant même l’émergence des grands modèles de langage, a profondément transformé les méthodes statistiques. A l’Insee, et plus largement dans le service statistique public, la datascience a favorisé de multiples innovations irriguant les méthodes statistiques. Elle a conduit à l’utilisation de méthodes d’apprentissage statistique (machine learning) et leurs applications prometteuses dans les domaines de la codification, des redressements et de l’imputation. Elle a également favorisé la combinaison des sources de données via des appariements, permettant de croiser les informations et d’enrichir les analyses. Elle a permis l’exploration de données émergentes. Dans cet article, on évoquera ces trois évolutions majeures : apprentissage statistique ; apport des appariements ; exploration de données émergentes. Ce ne sont bien sûr pas les seules innovations menées à l’Insee, dont un panorama plus large peut être trouvé dans un billet de blog de l’Insee (J.-L. Tavernier, 2025). L’émergence de l’intelligence artificielle générative ouvre également de nouvelles perspectives qui ne sont pas abordées ici.
L’apprentissage statistique : des méthodes souples pour catégoriser
Secteur d’activité, profession, commune, poste de dépenses des ménages, …. Les opérations de codification sont très nombreuses pour élaborer les statistiques publiques, et peuvent parfois être complexes en raison de la taille des nomenclatures. Les nouvelles méthodes d’apprentissage statistique offrent davantage de souplesse que les outils précédents ; elles permettent de s’adapter plus facilement dans le cas où les données en entrée évoluent et elles améliorent l’efficacité de la codification.
Pour donner un exemple, l’Insee doit coder le secteur d’activité des entreprises à partir de leurs déclarations. Jusqu’en 2022, les déclarations de la ou des activités des entreprises étaient rédigées par des experts et présentaient une certaine régularité. Avec la mise en place du guichet unique des formalités des entreprises, les chefs d’entreprises décrivent désormais leur activité dans un champ de texte libre. Face à ces évolutions, il a été décidé de travailler avec des modèles d’apprentissage statistique. La codification à partir des champs de texte libre fournis par les chefs d’entreprise est une tâche complexe : les descriptions d’activité sont relativement courtes, contiennent donc peu d’information statistique et peuvent inclure des fautes d’orthographe. Pour une telle tâche, les méthodes traditionnelles d’analyse textuelle sont souvent insuffisantes, tandis que les méthodes basées sur des réseaux de neurones donnent de meilleurs résultats.
Pour cette codification, l’Insee a adopté un modèle d’apprentissage supervisé. Le modèle se base sur une vectorisation de chaque libellé décrivant l’activité de l’entreprise ; cela consiste à associer à chaque mot une représentation sous la forme d’un vecteur (R. Avouac, T. Faria, F. Comte, 2025). Un texte est alors représenté comme une collection de représentations vectorielles de chacun des mots qui le composent. Plus précisément, cette représentation vectorielle est calculée sur les mots, mais aussi sur des n-grammes de mots et de caractères, fournissant ainsi plus de contexte et réduisant les biais liés aux fautes d’orthographe.
Il faut relier cette représentation vectorielle des libellés au secteur d’activité correspondant. Ces modèles d’apprentissage statistique nécessitent d’importantes données d’entraînement. Les données codées auparavant, dans l’ancien système déclaratif, ont fourni des premières sources d’entraînement ensuite complétées par une labellisation manuelle des données issues du guichet unique des formalités des entreprises.
Une fois entraîné, le modèle peut faire des « prédictions » de secteur d’activité. Il calcule un indice de confiance pour chaque prédiction. Pour une description textuelle donnée, si l’indice de confiance dépasse un seuil déterminé, la description est automatiquement codée. Sinon, un agent intervient, assisté par les cinq suggestions les plus probables du modèle.
Les modèles doivent être surveillés en permanence pour éviter une dégradation des performances. Par exemple, le mot « Uber » était habituellement associé à des codes liés aux services de taxis. Cependant, avec l’apparition des services de livraison de repas comme « Uber Eats », cette relation entre le libellé et le code associé a changé. Une veille statistique est donc cruciale pour ajuster les modèles.
Un autre exemple peut être donné par la codification des dépenses des ménages dans l’enquête Budget des familles. Cette enquête ambitieuse cherche à mesurer très précisément les multiples postes de dépenses des ménages. Pour l’enquête qui est actuellement en cours de collecte, les ménages ont pour la première fois le choix entre renseigner leurs dépenses dans un carnet papier comme auparavant ou télécharger une application smartphone qui prend en compte les photographies des tickets de caisse. Comme, par ailleurs, le calcul de l’inflation mensuelle repose partiellement sur des données de caisse, des bases de données reliant intitulés de produits et nomenclature de dépenses existent déjà. En parallèle, un test de l’enquête réalisé en 2024 a permis de constituer un autre corpus de 16 000 lignes, codées manuellement. Ces différentes bases seront utilisées et permettront, on l’espère, d’obtenir un modèle puissant de codification des lignes de dépenses.
Insertion professionnelle des apprentis, patrimoine immobilier et taxe foncière, … : l’apport des appariements
Dans l’enquête Budget des familles, et plus largement dans les enquêtes de l’Insee auprès des ménages, la mesure de leurs revenus repose sur l’utilisation de fichiers fiscaux et sociaux, permettant une mesure plus fiable qu’avec des données déclaratives. Cela se fait par l’appariement entre les données de l’enquête et des fichiers administratifs, c’est-à-dire la combinaison de ces données au niveau de chaque ménage.
Combiner différentes sources permet une observation plus riche et plus efficace. La plupart des instituts de statistique utilisent cette technique pour la production de données statistiques, en lien avec l’utilisation croissante de données administratives, souvent très précises mais très ciblées quant à leur contenu, et qui demandent donc à être complétées.
Différentes méthodes, déterministes ou probabilistes, existent pour réaliser des appariements (H. Koumarianos, O. Lefebvre et L. Malherbe, 2024). Pour évaluer la qualité d’un appariement, il est nécessaire de définir des objectifs et de réaliser un arbitrage entre les faux négatifs (ou paires concordantes oubliées) et les faux positifs (paires non concordantes acceptées). La notion de qualité est toujours liée à l’usage envisagé. Ainsi, lorsque les techniques d’appariement sont utilisées à des fins opérationnelles (dans le cadre d’opérations de gestion administrative par exemple), on porte une grande attention à chaque résultat individuel et on cherche le plus souvent à éviter les faux positifs (meilleure précision possible). Dans un contexte statistique, la précision est souhaitable, mais on cherche également à éviter un biais de représentativité induit par un défaut de rappel.
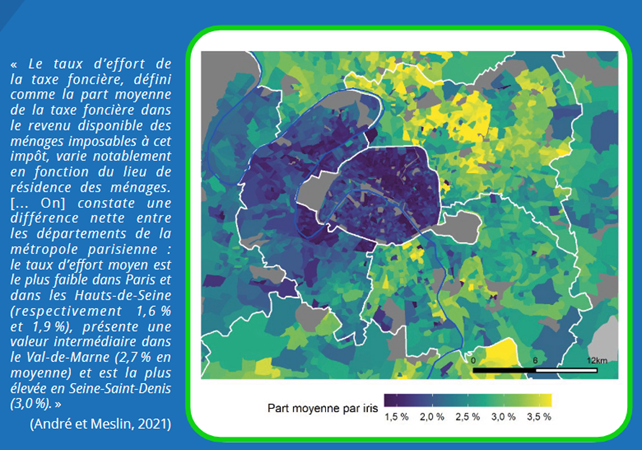
Les appariements de données se développent ces dernières années au sein de la statistique publique, portés à la fois par une demande croissante de données enrichies, par des données administratives plus nombreuses et par l’augmentation des ressources computationnelles. On peut ainsi citer Fidelimmo (M. André et O. Meslin, 2022), qui permet de répondre maintenant à des questions portant par exemple sur la taxe foncière : quel est le taux d’imposition lié à la taxe foncière ; comment est-il réparti ? (voir graphique). On peut citer également InserJeunes (L. Midy, 2021), qui permet une mesure plus fine de l’insertion professionnelle des apprentis, au niveau de chaque établissement ; ou Sirus (A. Hachid et M. Leclair, 2022), qui construit un répertoire statistique des entreprises en combinant différentes sources.
Prospecter de nouvelles sources de données
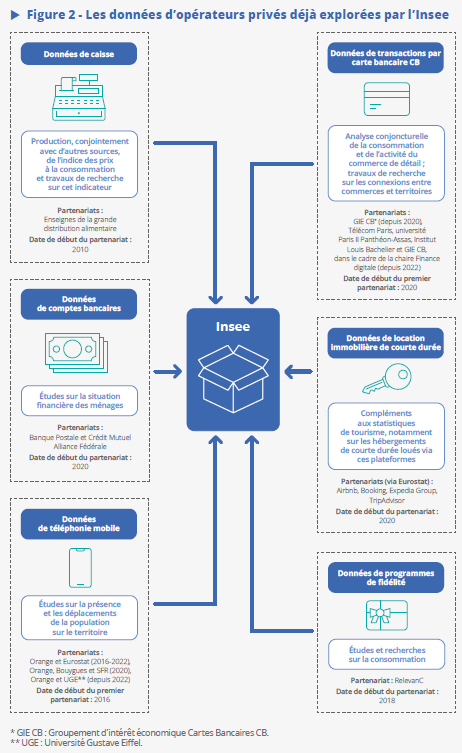
La numérisation de l’activité des entreprises a permis également à ces dernières de développer des bases de données liées à leurs processus de production, utilisées en général pour des objectifs opérationnels, mais qui peuvent parfois être ré-utilisées pour des enjeux statistiques. C’est le cas par exemple des données de caisse des enseignes de la grande distribution (super et hyper-marchés). Ainsi, l’Insee a intégré les données de caisse des grandes surfaces à prédominance alimentaire dans la production de l’indice des prix à la consommation et a étendu ses travaux exploratoires aux données de téléphonie mobile, de transactions par carte bancaire, de comptes bancaires ou encore de locations touristiques de courte durée (voir schéma).
Ces nouvelles sources enrichissent la connaissance économique et sociale, mais présentent souvent des limites : couverture partielle, imprécisions géographiques ou temporelles, et absence de variables sociodémographiques. Leur exploitation nécessite des partenariats renforcés avec des opérateurs privés, des infrastructures sécurisées, et une méthodologie rigoureuse (R. Lesur, 2025).
Les données de caisse sont exhaustives sur leur périmètre : l’Insee reçoit toutes les données des super et hyper-marchés. L’intégration de ces données dans un dispositif statistique est donc possible, sans risquer des double comptes ou des problèmes de couverture. Outre leur utilisation dans le calcul de l’inflation, ces données permettent d’affiner certaines analyses telles que celle de l’impact de la période de forte inflation sur la consommation alimentaire : les comportements de descente en gamme ont ainsi contribué pour deux points à la baisse de la consommation alimentaire, et les prix des produits d’entrée de gamme ont augmenté sensiblement plus vite que les autres (éclairage de la Note de conjoncture de l’Insee de mars 2026).
Pour les autres données, la couverture est souvent partielle, ce qui rend plus fragile l’utilisation pour produire des statistiques. Ces données peuvent néanmoins permettre de mener des études, par exemple d’analyser des comportements des personnes ou des entreprises, en précisant bien leur champ spécifique. C’est ainsi le cas de l’étude menée dans le cadre de la note de conjoncture de l’Insee sur le taux d’épargne : au sein des clients de La Banque Postale, les revenus des retraités ont fortement augmenté en 2024 mais la consommation n’a pas suivi, ce qui a contribué aux deux tiers de la hausse du taux d’épargne (éclairage de la Note de conjoncture de l’Insee de juin 2025).
L. Tavernier, L’innovation irrigue toute la statistique publique, billet de blog de l’Insee, juin 2025
Avouac, T. Faria, F. Comte, L’apport des technologies cloud pour industrialiser le processus d’innovation statistique, document de travail de l’Insee n°M2025/05, 2025
Koumarianos, O. Lefebvre, L. Malherbe, Les appariements : finalités, pratiques et enjeux de qualité, Courrier des statistiques N11, 2024
André et O. Meslin, Patrimoine immobilier des ménages : enseignements d’une exploitation de sources administratives exhaustives, Courrier des statistiques N7, 2022
Midy, Un outil d’appariement sur identifiants indirects : l’exemple du système d’information sur l’insertion des jeunes, Courrier des statistiques N6, 2021
Hachid et M. Leclair, Sirus, le répertoire d’entreprises au service du statisticien, Courrier des statistiques N8, 2022
Lesur, Sources de données privées : panorama et perspectives, Courrier des statistiques N13, 2025
Note de conjoncture juin 2025, éclairage, En 2024, les revenus des retraités clients de La Banque Postale ont fortement augmenté mais leur consommation n’a pas suivi, ce qui contribuerait aux deux tiers de la hausse du taux d’épargne
Note de conjoncture mars 2026, éclairage, Durant la période inflationniste, les comportements de descente en gamme ont contribué pour deux points à la baisse de la consommation alimentaire, et les prix des produits d’entrée de gamme ont augmenté sensiblement plus vite que les autres
Big Data et Statistiques, Economie et Statistique/Economics and Statistics, Insee, 1ère partie, n°505-506, 2018, 2ème partie n°509, 2019
Dossier Statistiques – Sommaire :
-
- Editorial
- De la causalité à la corrélation : une histoire riche en réflexions
- L’IA générative : une histoire de mathématiques – Voyage au cœur des équations qui font parler les machines
- Origine et fondements statistiques de l’hybridation des sources de données
- Les données synthétiques : promesses et réalités
- Innovation et datascience à la DGFiP : entretien avec Benoît Rouppert, délégué à la transformation numérique
- Les innovations en datascience à l’Insee : apprentissage statistique et nouvelles sources de données
- Les sondages électoraux en France à l’aune du contrôle de la Commission des Sondages

Auteure de publications académiques en économie empirique et évaluation de politiques publiques, dans les domaines du marché du travail et de l’éducation, elle a été membre du Conseil d’analyse économique de 2015 à 2020.
Commentaires récents