
Les méthodes statistiques fondées sur des échantillons probabilistes ont longtemps constitué, au cours du XXe siècle, le socle de la production d’informations quantitatives fiables dans de nombreux domaines, qu’il s’agisse de statistique publique, d’économie, d’épidémiologie ou de sciences sociales. Leur force réside dans leur cadre théorique rigoureux, qui permet de produire des estimations non biaisées et assorties d’une mesure de précision. Toutefois, la demande croissante d’informations plus fréquentes et plus granulaires met en évidence les limites structurelles des approches uniquement basées sur des échantillons.
Ces limites sont particulièrement manifestes dans la production de statistiques locales, où les estimations directes issues des enquêtes souffrent d’une variance élevée, voire deviennent inexploitables. Pour répondre à ces enjeux, de nombreux instituts statistiques, entreprises et organismes de recherche ont développé des approches hybrides, combinant données d’enquêtes, sources administratives, données de recensement ou données massives.
Les travaux concernant l’estimation sur petits domaines illustrent bien cette évolution (Pratesi et al, 2024) : l’intégration de sources auxiliaires et le recours à des modèles hiérarchiques permettent d’améliorer significativement la précision des estimations, tout en conservant un ancrage dans les propriétés de l’échantillonnage probabiliste.
La mesure d’audience n’échappe pas à cette dynamique d’évolution profonde des méthodes : la fragmentation des usages et la multiplication des accès aux contenus met les instituts au défi de pallier les limites des approches par sondage en utilisant la profondeur de données massives aujourd’hui disponibles.
Après une présentation générale du principe d’hybridation des sources de données, nous détaillerons une application récente à la mesure d’audience.
Un principe ancien en théorie des sondages
Si le terme « hybridation » est apparu assez récemment dans le contexte de la statistique, le concept est ancien et trouve son origine dans les travaux fondateurs de la théorie des sondages. Le principe est simple : « lorsqu’on dispose d’une information auxiliaire, il faut chercher à l’utiliser » (Ardilly, 2006). Deville & Särndal (1992) ont formalisé le cadre des estimateurs par calage en sondage, dont l’objectif est d’améliorer l’estimation des totaux de population en utilisant des informations auxiliaires connues.
Les méthodes d’hybridation se sont sophistiquées avec la nature des données traitées et la puissance des outils capables de les traiter, mais la philosophie reste la même : utiliser plusieurs sources de données pour en créer une nouvelle plus fine ou plus riche.
La logique de la mesure hybride repose sur quatre grands principes fondamentaux.
– Complémentarité : aucune source ne suffit à elle seule. L’objectif est de combler les lacunes d’une source par les qualités d’une autre.
– Alignement temporel et structurel : pour combiner des données, il faut qu’elles soient alignées dans le temps (par exemple, sur la même période) et dans leurs définitions (unités de mesure comparables).
– Modélisation : l’hybridation passe par la construction d’un modèle statistique pour combiner les différentes sources de données.
– Gouvernance des sources : une mesure hybride suppose un cadre clair, et en particulier la plus grande transparence sur les données partagées.
Les grandes familles d’approches
Il existe de nombreuses méthodes statistiques de rapprochement de données de sources différentes, voire des combinaisons de plusieurs méthodes statistiques. On peut distinguer quelques grandes familles répondant chacune à des besoins distincts.
Fusion statistique
Basée sur les techniques d’imputation, elle consiste à rapprocher plusieurs bases de données afin de créer un ensemble enrichi, cohérent et plus complet. Elle est utilisée lorsqu’aucune source ne contient l’ensemble des variables d’intérêt utiles et que les différentes sources de données ne peuvent pas être directement appariées à l’aide d’un identifiant commun.
L’objectif est de reconstituer une base de données similaire à ce que l’on aurait obtenu si toutes les variables avaient été collectées sur les mêmes individus. Le rapprochement des bases de données s’appuie sur la similarité des individus sur un ensemble de variables communes aux différentes bases : on définit une distance entre les individus des différentes bases et on les associe ensuite en fonction de leur similarité.
La fusion permet de limiter le fardeau de réponse des panélistes ou interviewés et de reconstituer une base de données complète similaire aux données d’origine et donc facilement exploitable dans des outils de restitution classiques. En revanche, les variables spécifiques à chaque base de données ne sont jamais observées conjointement. La qualité de la fusion repose donc fortement sur le pouvoir explicatif des variables communes sur les variables spécifiques. En l’absence de variables communes pertinentes, la fusion sera proche de l’aléatoire.
Calage
Cette approche est utilisée lorsqu’on dispose d’une source de données issue d’un échantillon ou d’un panel et d’une autre source de mesure exhaustive. Dans ce cas, on veut utiliser l’information issue de la mesure exhaustive, qui correspond à un total connu sur l’ensemble de la population, pour améliorer la précision statistique, réduire la variabilité des résultats ou corriger un biais de sélection sur l’échantillon ou le panel. L’approche consiste à introduire des contraintes de calage supplémentaires dans le redressement de l’échantillon ou du panel.
Le calage assure la cohérence des deux sources de données sans avoir à en modifier la structure. Par ailleurs, il ne nécessite pas d’avoir accès à la donnée brute de la mesure exhaustive, d’une volumétrie souvent très importante, mais uniquement aux totaux sur les variables de calage. En revanche, les différentes sources de données doivent être parfaitement comparables, ce qui n’est pas toujours nativement le cas. Des pré-traitements peuvent donc être nécessaires pour mettre en cohérence les périmètres mesurés et les indicateurs calculés.
Profiling
Il est utilisé lorsqu’on dispose d’une source de données très qualifiée, généralement issue d’un échantillon ou d’un panel, et d’une autre source de mesure exhaustive et que l’on veut enrichir la mesure exhaustive à l’aide des informations, souvent très riches, issues de l’autre source. En effet, la donnée exhaustive permet d’observer des usages encore rares ou occasionnels qu’un échantillon ne peut mesurer avec précision.
L’approche consiste à construire un modèle statistique de qualification sur les données de l’échantillon ou du panel et de l’appliquer ensuite sur la donnée exhaustive pour l’enrichir.
Elle améliore la compréhension des usages émergents ou rares sans avoir à augmenter significativement la taille des échantillons. Cependant les données exhaustives étant généralement collectées en silo, les variables explicatives à disposition pour la modélisation sont relativement pauvres, ce qui limite la capacité d’un modèle à estimer des profils de manière fiable.
Génération de population synthétique
La génération de population synthétique n’est pas propre aux approches hybrides mais elle peut être utilisée comme étape préalable au rapprochement de différentes sources de données. Elle est particulièrement utile lorsqu’au moins une source de données provient d’une mesure exhaustive. Cette approche est utilisée à l’origine pour l’analyse spatiale à un niveau fin. Elle consiste à construire un ensemble exhaustif et représentatif de la population sur lequel peuvent être distribués des résultats d’enquêtes ou de panels et des data. Cette redistribution pourra faire appel à des méthodes déterministes lorsqu’un identifiant commun est disponible entre les différentes sources ou à des méthodes stochastiques ou probabilistes dans le cas contraire. Les techniques de fusion ou de qualification détaillées précédemment pourront s’appliquer sur une population synthétique, tout comme les techniques de probabilisation.
Ainsi sont combinées différentes sources sans qu’elles soient nécessairement sur des univers strictement comparables et elle facilite la préservation des caractéristiques des données d’origine. Elle permet d’envisager l’exploitation à grande échelle de données individuelles très fines, sans se heurter aux problèmes de gestion de la confidentialité de ces données.
La qualité et la conformité de la population synthétique sont très dépendantes de la quantité et de la granularité des informations mises à disposition par les instituts nationaux de statistique. Ensuite, comme toute approche par modèle, la fiabilité des résultats dépend du pouvoir explicatif des variables communes sur les variables spécifiques.
Application à la mesure d’audience des médias
La mesure d’audience a pour objectif de quantifier et qualifier les personnes exposées à un contenu, chaîne de télévision, station de radio, titre de presse, site web ou tout autre média. Les premiers dispositifs apparus au début du XXe siècle se sont appuyés sur des enquêtes puis sur des panels : un « petit » nombre d’individus suivis dans le temps, soigneusement recrutés afin de représenter la population de référence.
De nombreux facteurs contribuent aujourd’hui à rendre de plus en plus complexe la mesure d’audience. Tout d’abord, les médias évoluent et leurs usages sont de plus en plus fragmentés. Mesurer avec précision l’audience de la multitude de contenus proposés nécessiterait d’accroître significativement la taille des échantillons. Par ailleurs, la digitalisation des médias offre désormais d’autres sources de données : les données voie de retour des boxes opérateurs ou des sites et applications des éditeurs.
C’est pourquoi la mesure d’audience d’Internet opérée par Médiamétrie en France est devenue hybride en 2012 (Dudoignon et al, 2018) et s’appuie sur deux sources : un panel d’individus et une mesure exhaustive du trafic des sites et applications. Une expérimentation a par ailleurs été menée pour la mesure d’audience de la télévision combinant un panel d’individus et les données voie de retour des boxes des opérateurs (Dudoignon et al, 2018).
Plus récemment, a émergé le besoin pour les annonceurs de disposer d’une vision unifiée, fiable et comparable de l’exposition publicitaire sur l’ensemble des médias. La solution proposée, détaillée ci-après, repose également sur une approche hybride combinant données exhaustives issues des différents fournisseurs et données issues d’un panel.
Contexte du projet de mesure cross-media publicitaire
La World Federation of Advertisers (WFA), organisation professionnelle internationale représentant les annonceurs, a publié en 2019 un appel à projets pour une mesure cross-media publicitaire répondant aux besoins croissants des annonceurs en matière de cohérence, de comparabilité et de robustesse des indicateurs de mesure de performance de leurs campagnes publicitaires. L’ambition affichée est de définir une approche générique reposant sur une utilisation conjointe de données issues de multiples environnements (web, plateformes OTT, agrégateurs) et données issues de panels, tout en respectant des contraintes fortes de confidentialité. Des groupes de travail réunissant de nombreux acteurs de la mesure ont été organisés aux Etats-Unis par la WFA et en 2020 a été présenté le cadre méthodologique et technique retenu.
Description générale du modèle WFA et de ses étapes
La WFA propose un processus structuré en plusieurs étapes successives.
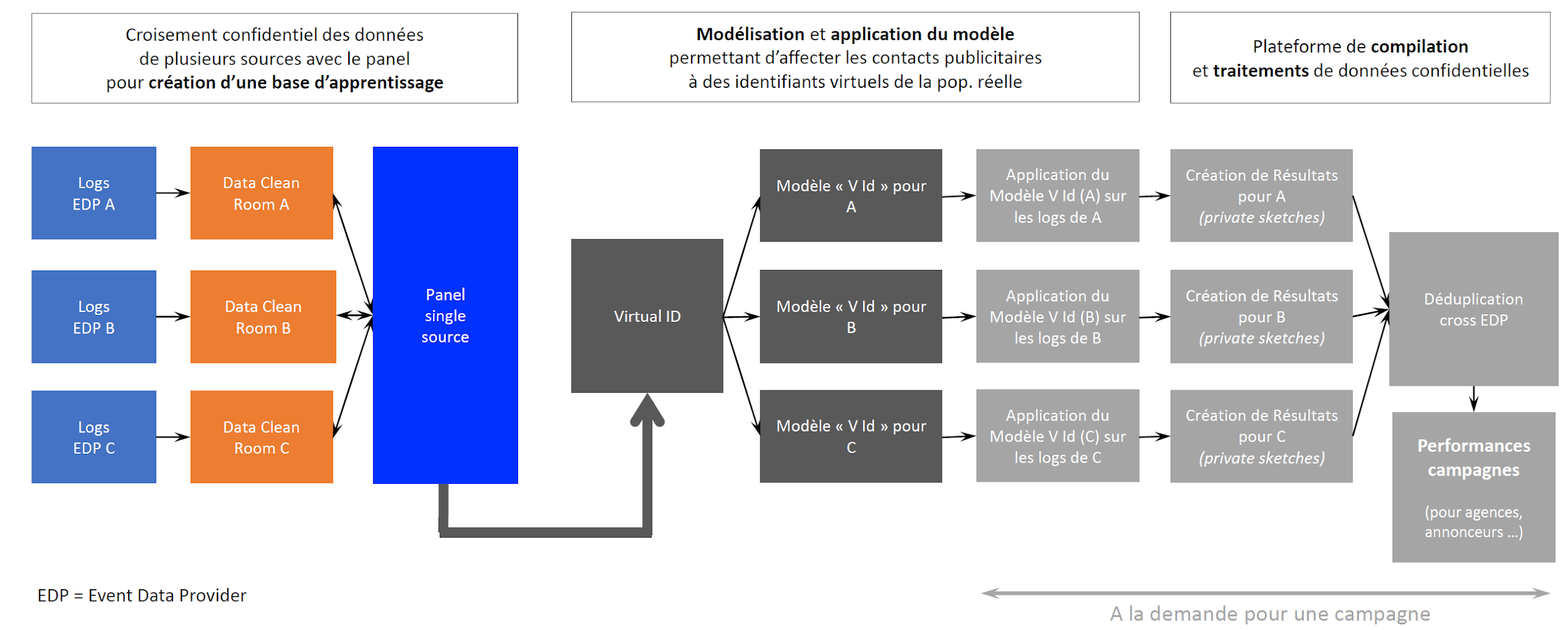
Dans un premier temps, des données d’entrée de nature hétérogène sont collectées auprès de différents fournisseurs (éditeurs, plateformes, agrégateurs). Constituées principalement de logs ou de cookies, elles sont préalablement anonymisées puis associées à des données issues d’un panel. Ce panel « single source » permet d’estimer de manière précise les duplications entre les différents fournisseurs de données pour les campagnes suffisamment puissantes. Le panel constitue ici la source de référence permettant de relier les volumes observés de logs ou de cookies à des indicateurs de couverture dédupliquée sur la cible de population considérée.
La deuxième étape correspond à la phase d’apprentissage du modèle, au cours de laquelle les performances des campagnes tests mesurées sur le panel dans l’étape précédente sont utilisées afin d’estimer les paramètres décrivant la distribution des expositions publicitaires au niveau individuel.
Une fois le modèle estimé, celui‑ci est transmis à chacun des fournisseurs de données impliqués dans le dispositif, accompagné de ses paramètres spécifiques. Ces derniers appliquent ensuite leur propre modèle pour chaque campagne mesurée, en générant des identifiants virtuels (VID).
Les sorties produites par l’ensemble des fournisseurs de données sont alors agrégées afin d’estimer les performances globales de la campagne, avant d’être restituées aux utilisateurs finaux.
Le modèle DMM : fondements et hypothèses
La base statistique de la méthodologie est le Dirac Mixture Model (DMM). Ce modèle repose sur l’hypothèse selon laquelle la population cible peut être décomposée en un nombre fini k de groupes latents d’individus présentant des comportements homogènes vis‑à‑vis des expositions publicitaires.
Chaque groupe représente une proportion  de la population cible (avec
de la population cible (avec  ), i = 1 à k, et est caractérisé, pour chaque dimension du modèle, par un paramètre décrivant l’intensité moyenne des expositions.
), i = 1 à k, et est caractérisé, pour chaque dimension du modèle, par un paramètre décrivant l’intensité moyenne des expositions.
Au sein de chaque groupe, le nombre de logs ou de cookies associés à un individu est supposé suivre une loi de Poisson, ce qui permet de modéliser la variabilité des contacts publicitaires. L’estimation du modèle consiste alors à déterminer conjointement le nombre de groupes, leurs poids relatifs et les paramètres de la loi de Poisson correspondants, à partir des campagnes tests pour lesquelles le volume total de logs et la couverture sont connus.
Le modèle VID ainsi défini revient à un processus de tirage aléatoire avec remise d’individus au sein des groupes, effectué indépendamment selon les dimensions considérées.
Conclusion et perspectives
Dans un contexte de délinéarisation et de fragmentation croissantes des usages, les frontières entre diffuseurs linéaires et plateformes de streaming s’estompent et les logiques de convergence s’accélèrent. Cette transformation se traduit pour les mesureurs d’audience par une complexité croissante et une nécessité d’adapter les protocoles de mesure.
L’hybridation des données de panel avec des données exhaustives de fournisseurs tiers apparaît comme une évolution inéluctable et généralisée. Mais pour que ces données puissent être une composante de la mesure d’audience, elles doivent répondre aux exigences décrites dans la réglementation européenne. L’EMFA (European Media Freedom Act) établit un cadre juridique visant à garantir que tout système de mesure d’audience, y compris propriétaire, respecte des principes de transparence, d’impartialité et de vérifiabilité, permet l’accès aux méthodologies et résultats, soit soumis à des audits indépendants et s’inscrive dans des mécanismes d’autorégulation largement reconnus par l’industrie. Le DMA (Digital Markets Act) oblige quant à lui les gatekeepers (par ex. Google, Meta, Apple, Amazon) de partager avec les éditeurs et annonceurs les données nécessaires à une mesure indépendante et de permettre l’auditabilité des performances publicitaires. Ensemble, ils visent à instaurer des conditions de marché permettant une mesure indépendante, transparente et comparable et renforcent le rôle central de Médiamétrie dans l’écosystème.
Bibliographie
Ardilly, P. (2006). Les techniques de sondage, France, Technip.
Deville, J.-C. & Särndal, C.-E. (1992). Calibration Estimators in Survey Sampling, Journal of the American Statistical Association, Vol. 87, 418, 376-382. https://doi.org/10.1080/01621459.1992.10475217
Dudoignon, L., Le Sager, F. & Vanheuverzwyn, A. (2018). Big Data and Audience Measurement: A Marriage of Convenience ? Economie et Statistique / Economics and Statistics, 505-506, 113-146. https://doi.org/10.24187/ecostat.2018.505d.1969
Pratesi, M., Siciliano, R. & Lahiri, P. (2024). Special issue SMA: big data and alternative data sources for small area estimation. Statistical Methods & Applications, 33, 1025-1026. https://doi.org/10.1007/s10260-024-00765-x
Rosanvallon, J. & Vanheuverzwyn, A. (2025). Hybride & IA : Les nouvelles générations de mesure face aux enjeux de la mesure médias, Livre blanc.
Dossier Statistiques – Sommaire :
-
- Editorial
- De la causalité à la corrélation : une histoire riche en réflexions
- L’IA générative : une histoire de mathématiques – Voyage au cœur des équations qui font parler les machines
- Origine et fondements statistiques de l’hybridation des sources de données
- Les données synthétiques : promesses et réalités
- Innovation et datascience à la DGFiP : entretien avec Benoît Rouppert, délégué à la transformation numérique
- Les innovations en datascience à l’Insee : apprentissage statistique et nouvelles sources de données
- Les sondages électoraux en France à l’aune du contrôle de la Commission des Sondages

Commentaires récents