
Variances remercie les deux auteurs et l’Insee pour cet article en deux volets tiré du Courrier des Statistiques de décembre 2024 : L’économie racontée par les données bancaires − Courrier des statistiques N12 – 2024 | Insee
Avertissement : l’article original a été scindé en deux parties pour publication dans Variances. Ci-dessous, la partie relative au traitement au sein des banques. Le second volet couvrira le traitement des statisticiens.
Depuis la crise sanitaire en 2020, l’Insee bénéficie d’un accès à des échantillons anonymisés de comptes bancaires de La Banque Postale et du Crédit Mutuel Alliance Fédérale. Ces données, riches en informations, ont permis de documenter l’évolution de la situation financière des ménages en temps réel lors de la crise inédite de la Covid-19, puis lors de l’épisode inflationniste en 2022. Elles ont également permis de documenter la situation quotidienne des ménages, mettant en lumière des épisodes de découvert en fin de mois, et d’évaluer une politique publique en mesurant les impacts financiers, distributifs et environnementaux de la remise à la pompe instaurée en 2022 à la suite de la hausse des prix du carburant.
Les données bancaires sont une mine d’informations précieuses, mais leur utilisation soulève de nombreux défis. Après quatre années d’utilisation, un premier bilan de leur exploitation est proposé dans cet article. Comment construire des concepts qui ont un sens économique à partir de ces données ? Comment s’assurer de leur représentativité ? Quels sont les apports de ces données pour la statistique publique ? Si elles ne permettent pas de remplacer les données d’enquêtes et fiscales, elles complètent les analyses conjoncturelles. En outre, elles permettent de répondre à des questions anciennes sur la consommation et l’épargne des ménages auxquelles les sources traditionnelles ne pouvaient apporter de réponses. Dans cet article, sont détaillés les enjeux et les difficultés pour utiliser des données qui proviennent d’acteurs privés et n’ont pas été produites à des fins statistiques, mais à des fins de gestion par les banques.
Les relevés de comptes bancaires en disent beaucoup sur nos vies. Lorsque les fins de mois sont difficiles, les soldes des comptes sont au plus bas et les découverts plus fréquents. Lorsque nous perdons notre emploi, un virement régulier de salaire peut être remplacé par un virement de France Travail. Même les départs en vacances ne passent pas inaperçus ; les dépenses de transport et d’hébergement augmentent, de même que les dépenses réalisées à l’étranger. Les données bancaires, très riches en information, permettent donc des exploitations variées.
Dans le premier volet de l’article, nous reviendrons d’abord sur le contexte qui a permis l’accès de l’Insee à ces données ; le mouvement d’ouverture vers des données d’origine privée a été accéléré par la crise sanitaire. Ensuite, nous expliciterons comment ces données sont produites à partir des transactions des clients
Une aubaine pour décrire la situation financière des ménages pendant la crise sanitaire
En 2020, la crise sanitaire et le confinement à grande échelle de la population ont provoqué un choc sur l’économie aussi soudain qu’inédit. À l’Insee, le suivi de la conjoncture en a été bouleversé, conduisant notamment au recours accru à des données nouvelles, plus rapidement disponibles que les données traditionnelles (Pouget, 2020). Parmi les nouvelles sources mobilisées, les données de comptes bancaires se sont avérées précieuses car très détaillées et rapidement disponibles. Pour l’Insee, ces données offraient une réelle opportunité pour conforter et enrichir les informations provenant des sources traditionnelles d’enquête avant que les données de sources fiscales ne soient disponibles. En outre, elles permettaient d’éclairer la situation financière des ménages sous un jour nouveau, grâce à des indicateurs atypiques pour la statistique publique mais très parlants pour le grand public, comme les montants présents sur les comptes en fin de mois ou la proportion de ménages à découvert.
L’intérêt de l’Insee pour ces données s’est concrétisé lorsque certaines banques, dans le contexte de la crise sanitaire, ont souhaité contribuer à l’analyse de la situation économique par la statistique publique. Crédit Mutuel Alliance Fédérale (CMAF) a ainsi permis un accès sécurisé à des données anonymisées de comptes bancaires d’un échantillon de sa clientèle dès 2020[1]. Des premières études sur l’évolution de la situation financière des ménages pendant la crise sanitaire ont résulté de cette collaboration (Insee Note de conjoncture, 2021). Cependant, utiliser des données provenant d’un seul réseau bancaire pouvait être insuffisant pour décrire l’ensemble de la population. La clientèle de CMAF étant plus aisée que la moyenne, ces données pouvaient notamment s’avérer inadéquates pour documenter la situation financière des plus fragiles. Or, le sujet était brûlant à l’époque, en plein cœur de la crise sanitaire. L’Insee a pris contact avec un second réseau : La Banque Postale (LBP). Il s’agit de l’établissement le plus à même de fournir des informations sur les clients bancarisés les plus fragiles, car le législateur lui a confié une mission d’accessibilité bancaire. Les informations de cette banque ont permis de montrer la stabilité des revenus, malgré la crise, y compris pour les plus modestes. Cela a conforté les estimations obtenues par le modèle de microsimulation Ines[2] qui concluait à un taux de pauvreté stable. Ce constat, à rebours des discours publics[3], rendait le recours à des données externes particulièrement précieux pour convaincre de la solidité des résultats obtenus avec les méthodes usuelles (Tavernier, 2022). Ainsi, la publication sur les données LBP a été programmée le même jour que la publication annuelle portant sur le taux de pauvreté, soit une dizaine de jours avant la journée mondiale de la pauvreté.
La crise inflationniste succédant à la crise sanitaire, les données bancaires ont de nouveau été mobilisées afin d’éclairer l’évolution de la situation financière des ménages dans ce nouveau contexte en 2022 et 2023.
Une nouvelle utilisation de « big data » privées dans la statistique publique
Si l’accès aux données bancaires a été accéléré par la crise sanitaire, il s’inscrit dans un contexte plus large d’utilisation par les instituts nationaux de statistiques de nouvelles données massives d’origine privée, comme les données de caisse (Leclair, 2019). Ces données, appelées communément « big data », peuvent inclure des informations aussi variées que celles d’annonces de logements, de téléphonie mobile ou de compteurs de gaz et d’électricité. Ces données procurent de nombreux avantages par rapport aux sources usuelles comme la haute fréquence ou la granularité (Blanchet et Givord, 2018). Mais il existe également de nombreux obstacles dans leur utilisation. Outre les enjeux de représentativité, ces données sont peu structurées, et leurs exploitations nécessitent donc d’importants investissements.
Avant d’être transformée en information utile au débat public, la donnée bancaire subit de nombreux traitements, du terminal de paiement aux tableaux ou graphiques des publications, en passant par les systèmes d’information des banques. Ce long chemin n’est pas propre aux données bancaires ou aux données privées et fait écho aux traitements réalisés lors d’utilisation de données administratives (Cotton et Haag, 2023), par exemple celles de propriétés immobilières (André et Meslin, 2022).
Nous allons décrire ce parcours de la donnée et les retraitements réalisés par la banque puis par le statisticien.
Parcours de la donnée bancaire : du système de gestion privé à une meilleure compréhension des comportements économiques
L’exploitation des données bancaires repose sur des partenariats étroits avec les banques. Le statisticien public ne se contente pas de récupérer et d’exploiter une base préexistante, il doit la construire progressivement et conjointement avec le partenaire bancaire. L’objectif est de transformer des données issues des processus de gestion de comptes bancaires en des tables de données individuelles agrégées au niveau ménage. Cette entreprise nécessite de nombreux échanges avec les banques. D’un côté, le statisticien doit expliciter ses besoins, de l’autre la banque doit détailler le contour des données qu’elle peut mettre à disposition. Les données s’enrichissent au fur et à mesure du partenariat au gré des besoins du statisticien et des contraintes des banques (encadré 1).
Encadré 1. Des partenariats étroits avec les banques qui facilitent la montée en puissance de l’utilisation des données bancaires à des fins statistiques
Des échanges réguliers avec les banques ont permis à l’Insee d’améliorer significativement l’exploitabilité des données depuis le début du partenariat. Ces collaborations étroites se sont d’ailleurs traduites par des co-publications avec les banques (de l’Insee avec La Banque Postale et du Conseil d’Analyse Économique (CAE) avec Crédit Mutuel Alliance Fédérale).
Les partenariats avec les banques ont également conduit à des projets d’expériences aléatoires sur certains clients. L’Insee mène actuellement une expérimentation en collaboration avec La Banque Postale, dans le but d’évaluer un dispositif d’accompagnement budgétaire, qui s’inscrit dans le cadre de la mission publique d’accessibilité bancaire de La Banque Postale, destiné aux clients en situation de fragilité financière. Le CAE a également estimé des propensions marginales à consommer, c’est-à-dire les montants dépensés par les ménages qui bénéficient d’une hausse de revenu, à partir d’une expérience sur des clients du CMAF (Boehm et alii, 2023).
Apparier à d’autres sources (tout en préservant l’anonymat) peut ouvrir d’autres perspectives d’études : grâce à un appariement avec des données publiques de diagnostic de performance énergétique (DPE)*, le CAE a étudié la performance énergétique des logements (Astier et alii, 2024). Au Danemark, des chercheurs ont également étudié la réaction des ménages lors d’une perte d’emploi en appariant les données bancaires des clients d’une grande banque danoise avec les données sur leurs employeurs** (Andersen et alii, 2023).
* Appariement réalisé par la banque à partir de l’adresse des clients.
** L’appariement repose sur une identification de l’employeur par le compte bancaire utilisé pour verser les salaires.
Du côté de la banque : des données de gestion privées aux bases de données statistiques
D’où viennent les données bancaires ?
Chaque jour, des millions d’opérations bancaires ont lieu. Toutes ces opérations sont enregistrées par le système d’information bancaire afin que l’argent circule entre les comptes des ménages et des entreprises. Une transaction bancaire génère un flux de données entre la banque émettrice et la banque acquéreur, en passant par plusieurs intermédiaires (figure 1). Par exemple, lors d’un paiement par carte chez un commerçant, le traitement du paiement se déroule généralement en trois étapes : l’autorisation, la compensation et le règlement. La phase d’autorisation a lieu au moment où le client insère sa carte dans le terminal de paiement du magasin. La banque du commerçant (banque acquéreur) interroge alors la banque du client (banque émettrice) via le réseau de cartes pour savoir si la transaction est approuvée. La banque émettrice renvoie ensuite une réponse, positive ou négative, qui parvient jusqu’au terminal de paiement et qui permet de valider ou refuser l’opération. En fin de journée, le commerçant transfère à sa banque un fichier récapitulant toutes les transactions enregistrées (début de l’étape de compensation). Celle-ci regroupe les informations pour l’ensemble de ses clients et les transmet à la banque émettrice, par l’intermédiaire du réseau de cartes, afin de préparer l’étape de règlement. Lors de cette dernière étape, trois règlements ont lieu (de manière indépendante, et pas nécessairement dans cet ordre) : la banque acquéreur reçoit les fonds de la banque émettrice, verse le montant dû au commerçant, tandis que la banque émettrice débite le compte du client.
Au-delà de ces flux, les banques collectent également des variables sociodémographiques afin de mieux connaître leur clientèle (profession, nombre d’enfants par exemple). Cela leur permet de proposer des services adéquats. Ces informations sont traditionnellement collectées lors des rendez-vous avec les conseillers en agence mais également de plus en plus via des questionnaires envoyés par courriel.
Figure 1 – Représentation des flux de données : du client de la banque jusqu’au statisticien
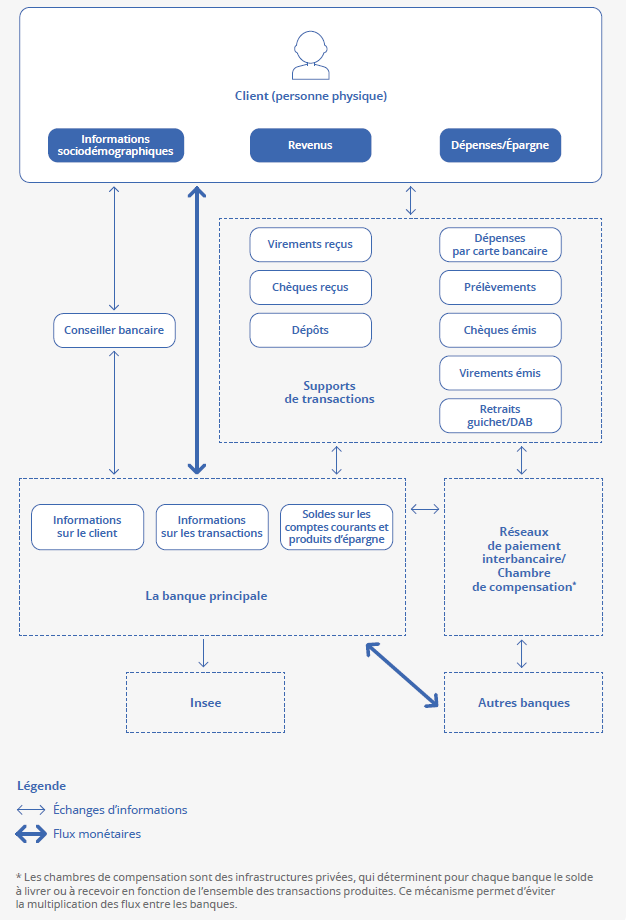
Sélection et transformation des données pour répondre aux besoins de la statistique publique
De manière itérative, à la suite de nombreux échanges visant à clarifier les données disponibles et l’expression des besoins de l’Insee, la banque sélectionne les données pertinentes, les anonymise et les transforme selon les étapes suivantes.
Tout d’abord, la banque opère une sélection des tables et des variables. Au sein de la masse de données stockées au sein de la banque à des fins de gestion (des centaines, voire des milliers de tables contenant chacune quelques dizaines de variables), la banque sélectionne les informations sur les transactions, les soldes, les crédits, les incidents bancaires, ainsi que les caractéristiques sociodémographiques de ses clients. Les données sont figées un mois donné, il arrive donc qu’il manque certaines transactions remontant avec un délai, notamment celles effectuées les derniers jours du mois.
Ensuite, la banque procède au tirage d’un échantillon. Une fois ces tables et variables rassemblées, la banque tire un échantillon de clients à mettre à disposition selon une méthodologie préalablement définie. Cette opération d’échantillonnage qui est monnaie courante dans la statistique publique est rare dans le monde bancaire. Le tirage se fait uniquement sur les clients dont la banque estime héberger les revenus et la majorité des opérations de consommation.
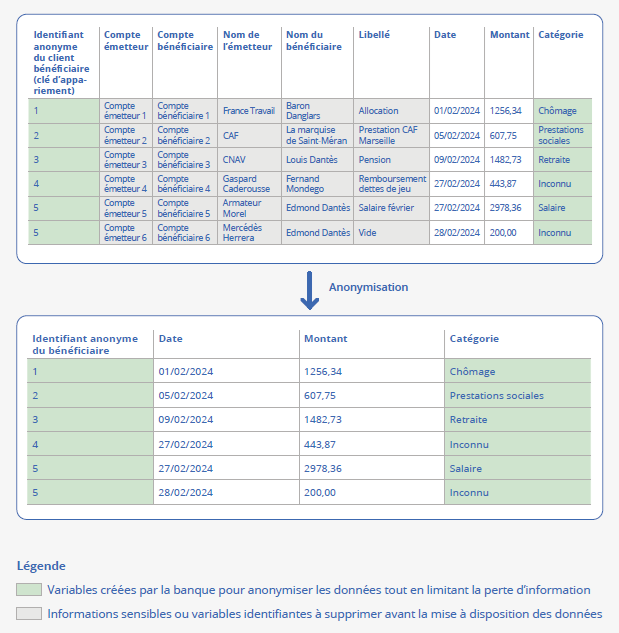
Puis la banque opère l’anonymisation des données. L’anonymisation (figure 2) implique la suppression de variables identifiantes comme le(s) nom(s) et adresse des clients mais également le(s) nom(s) d’émetteurs et les libellés des virements. Or, ces dernières variables sont utiles pour les analyses puisqu’elles permettent de repérer les salaires perçus par les clients, mais aussi les prestations sociales, les allocations chômage, les pensions de retraites, etc. Avant la suppression, la banque extrait donc les informations utiles et non identifiantes de ces variables (type d’émetteur, régularité de l’émetteur, libellé contenant des mots-clés comme « salaire », etc.). Il s’agit d’un compromis qui permet de garantir l’anonymat des clients, tout en limitant la perte d’information (Redor, 2023).
Enfin, la banque opère le transfert des données. Elle transmet les données et les métadonnées à l’Insee dans des environnements sécurisés, au format CSV via le Centre d’Accès Sécurisé aux Données (CASD) pour LBP, et sous la forme d’une base de données relationnelle via une machine virtuelle pour CMAF.
Figure 2 – L’anonymisation des données
Mots clés : Insee – Statistiques – Banques -Big data – Épargne – Revenu
[1] Le Conseil d’analyse économique (CAE) a demandé et obtenu un accès à des données anonymisées de Crédit Mutuel Alliance Fédérale. À la suite de ce partenariat, l’Insee a formulé la même demande.
[2] https://www.insee.fr/fr/information/2021951.
[3] Pendant la crise sanitaire de la Covid, le chiffre d’un « million de pauvres supplémentaires » était repris dans la presse (Le Monde, 2020). Ce chiffrage provenait d’associations caritatives. Les outils déployés par la statistique publique pour mesurer le taux de pauvreté (finalement stable en 2020) sont détaillés par la suite (Tavernier, 2022).