
Pourquoi des comptes distributionnels de revenu et de patrimoine
La mesure des inégalités de richesse et de leur dynamique, la compréhension des phénomènes à leur origine (inégalité de salaires, transmissions intergénérationnelles, inégalités de rendement du capital) et l’étude de l’impact des décisions de politique économique (politique monétaire, politique fiscale…) sur ces inégalités sont des éléments cruciaux pour éclairer le débat économique et social. Plus récemment, l’interaction entre la politique monétaire et les inégalités a également fait l’objet d’une attention accrue. En réponse à la crise financière mondiale, la politique monétaire s’est engagée dans une période prolongée d’accommodation monétaire, avec des mesures non conventionnelles telles que l’orientation prospective (« forward guidance ») et les achats d’actifs utilisées pour abaisser et aplatir la courbe des taux. Comme ces mesures ont tendance à avoir un impact plus important sur le prix des actifs à long terme que les variations des taux d’intérêt à court terme, cela a suscité des inquiétudes quant au fait que la politique monétaire bénéficie principalement aux ménages les plus riches. En outre, étant donné qu’il est de plus en plus reconnu que la répercussion de la politique monétaire dépend de la répartition des revenus et de la richesse, les banques centrales ont commencé à accorder plus d’attention à l’hétérogénéité des ménages.
Depuis les recommandations du rapport Stiglitz-Sen-Fitoussi (2009) et son invitation à aller au-delà des agrégats, différentes initiatives ont vu le jour : d’un côté, les Distributional National Accounts (DINA) produits par les chercheurs associés au World Inequality Lab (WIL) de T. Piketty et, de l’autre, les travaux au sein de groupes d’experts de l’OCDE-Eurostat et du réseau des banques centrales européennes (ESCB). Ces derniers cherchent à coupler les enquêtes ménages et les comptes nationaux afin d’élaborer des comptes nationaux distributionnels ou par grandes catégories de ménages (par décile). Le travail s’est réparti entre le groupe d’experts OCDE-Commission Européenne qui se concentre sur la construction de comptes distributionnels pour le revenu, la consommation et l’épargne (EG DINA) et celui de l’ESCB (EG DFA, 2020[1]) qui s’oriente sur la distribution du patrimoine.
Les données sources utilisées pour construire des comptes de patrimoine distribués
Alors que la recherche empirique sur les salaires et les revenus s’appuie largement, en France comme à l’étranger, sur des données individuelles, fondées pour une grande part sur des sources administratives, d’excellente qualité, celle sur la richesse n’est généralement réalisée qu’à partir de deux types de données individuelles : d’une part, les données de l’enquête Household Finance and Consumption Survey (HFCS) harmonisée au niveau européen dont le volet français n’est autre que l’enquête Histoire de vie et Patrimoine de l’Insee ; d’autre part, celles du WIL, construites à partir de données de revenus fiscaux « capitalisés » et d’imputations par classe de population. Même si les données HFCS n’ont pas la qualité des données administratives à moins d’être complétées et ajustées, l’ESCB a pris le parti de construire les comptes distributionnels de patrimoine à partir de cette enquête.
Les enquêtes sous-estiment le patrimoine détenu par les ménages
Malgré sa qualité, HFCS tend à sous-estimer le patrimoine détenu par les ménages, notamment dans sa composante financière. La sous-estimation des agrégats de la comptabilité nationale par les enquêtes n’est pas un phénomène spécifique à la France. Il est partagé à des degrés divers dans les autres pays européens. Le rapprochement de HFCS avec la comptabilité nationale met en évidence que les taux de couverture[2] des comptes nationaux par les enquêtes augmentent à mesure que le concept de patrimoine considéré est élargi : assez faible lorsqu’on ne considère qu’un concept étroit de patrimoine – le patrimoine financier, hors actions non cotées, fonds d’investissement, et assurance vie – (il est alors généralement inférieurs à 75 % dans les grands pays), pour augmenter lorsque le concept de patrimoine est élargi à l’ensemble des actifs financiers et non financiers. Certains pays paraissent moins performants, par exemple l’Italie et le Royaume-Uni. La France serait plutôt dans une position moyenne basse ; l’Espagne serait assez performante lorsque l’ensemble du patrimoine financier est considéré (graphique 1).
Graphique 1 – La couverture des comptes nationaux par les enquêtes Patrimoine du réseau européen HFCS
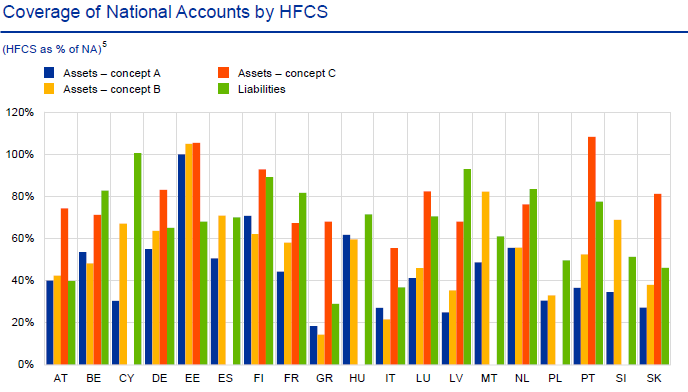
Source : HFCS 2010, 2014 ; EG-LMM (2020).
Note : Concept A : patrimoine financier restreint ; Concept B : patrimoine financier élargi (concept A + actions non cotées, fonds d’investissement, assurance vie et plans de retraite) ; Concept C : patrimoine élargi (concept B+ Logement et terrains et patrimoine professionnel des entrepreneurs individuels) ; Liabilities : crédits au passif des ménages.
Différentes raisons à cette sous-estimation par les enquêtes, en particulier en France, des agrégats de la comptabilité nationale peuvent être avancées :
– (1) à champ et concept identiques, les sources diffèrent : les encours d’actifs et de passifs financiers de la comptabilité nationale sont mesurés principalement à partir des données collectées auprès des établissements financiers. Par exemple, il n’y a pas toujours d’équivalence parfaite entre les actifs répertoriés par la comptabilité nationale et ceux recensés dans le questionnaire des enquêtes HFCS ce qui complique la comparaison. Le patrimoine professionnel est un bon exemple[3] ;
– (2) il est connu que la distribution du patrimoine est très concentrée vers les hauts patrimoines, suivant une loi de Pareto à partir d’un certain seuil (voir notamment Benhabib et Bisin, 2018) et que, généralement, les estimations de richesse dans les enquêtes sous-estiment le haut de la distribution. Le patrimoine des ménages les plus riches estimé par les enquêtes reste inférieur au patrimoine des ménages les plus riches dans la population, lesquels malgré leur très faible nombre, ont un poids très important dans le patrimoine total. Ce biais vers le bas s’explique par le fait que les taux de réponse des ménages aux enquêtes Patrimoine sont corrélés avec leur niveau de richesse, étant les plus faibles pour les ménages les plus riches. Autre élément d’explication de ce biais : un défaut de couverture des ménages les plus riches par les enquêtes : les ménages les plus riches sont exclus a priori du plan de sondage[4];
– (3) enfin, d’une part, les ménages ont souvent des difficultés à évaluer leur patrimoine à la valeur marchande, que ce soient les biens immobiliers ou les biens professionnels, ou encore les actions dans des entreprises non cotées (Arrondel et al., 1996 ; Accardo et al., 2014 ; Accardo, 2017). D’autre part, les ménages seraient aussi en grande majorité enclins à sous-déclarer leur patrimoine, à des degrés divers selon les types d’actifs et les pays, et d’autant plus qu’ils sont riches.
Quelle méthode pour « recaler » la moyenne de la distribution de l’enquête sur le patrimoine estimé par les comptables nationaux ?
L’enjeu a donc consisté à développer une méthode permettant de corriger les données d’enquête et de produire par pays et par type de patrimoine (logement, financier et professionnel) des séries trimestrielles recalées au niveau agrégé avec les agrégats des comptes de patrimoine. Ces séries, à ce jour produites à un stade expérimental, seront, après une phase de consultation auprès des utilisateurs de l’ESCB, publiées sous réserve de l’avis favorable du Conseil des Gouverneurs. Cette méthode distingue trois sources possibles d’écart entre la moyenne de la distribution donnée par l’enquête et la moyenne retracée par la comptabilité nationale. Ces sources d’écarts reprennent celles qui ont déjà été listées dans la partie précédente et appliquent une correction à chacun de ces écarts.
On souhaite tout d’abord identifier les « mauvaises déclarations » (problème, dit des « faux zéros »). Certains ménages déclareraient à tort, par oubli ou pour d’autres raisons, ne pas détenir certains avoirs (dépôts ou assurance vie par exemple). Il serait intéressant de recourir à un modèle statistique de type hurdle pour identifier les valeurs aberrantes par instrument et les corriger de manière systématique. Faute de données pertinentes, cette approche est difficile. Pour les dépôts uniquement (instrument financier caractérisé par un taux de couverture très faible dans de nombreux pays), une méthode d’identification et de correction des valeurs aberrantes basée sur trois critères statistiques – revenu, valeur du patrimoine détenu dans des actifs autres que les dépôts, catégorie socioprofessionnelle – a été retenue.
Ensuite on va redresser le haut de la distribution (déclaration des très riches). En effet, comme nous l’avons vu précédemment (cf. points 2 et 3), on mesure mal le patrimoine des ménages aisés. La méthode proposée pour corriger la difficulté à capturer les ménages les plus aisés consiste à « réestimer » le haut de la distribution, à savoir la distribution du patrimoine des ménages qui disposent d’un patrimoine d’au moins 1 million d’euros à l’aide d’une distribution de Pareto. Cet outil statistique associe, pour un montant de patrimoine donné, une probabilité qu’un ménage détienne ce montant de patrimoine. Il permet donc de reconstruire une distribution du patrimoine. La distribution de Pareto repose sur l’hypothèse d’une forte concentration des richesses dans le haut de la distribution de patrimoine, hypothèse vérifiée empiriquement par de nombreux travaux. Néanmoins, cette concentration est plus ou moins forte selon les pays. Il existe donc plusieurs formes possibles de la distribution de Pareto. Par conséquent, la difficulté consiste pour chaque pays à ré-estimer le degré de concentration des richesses pour déterminer la forme de distribution de Pareto qui lui correspond. α étant le paramètre de forme de la distribution, la méthode retenue pour obtenir une valeur α plus proche de la réalité consiste à ajouter des données externes à l’enquête, à savoir la valeur du patrimoine des quelques personnes les plus riches du pays, publiée chaque année dans la presse spécialisée (par les magazines Forbes, Challenges ou Capital par exemple). Il est ensuite possible de tracer une droite de régression pour connaître la valeur du paramètre α. La distribution de Pareto peut alors être utilisée pour corriger le haut de la distribution, en y ajoutant des ménages fictifs. L’ajout de ces ménages fictifs s’appuie sur un tirage aléatoire au sein de la distribution de Pareto précédemment estimée. La composition du patrimoine des ménages les plus aisés est ensuite déterminée à partir d’une enquête publiée dans The Economist et menée auprès des gestionnaires de fortune privée sur le patrimoine de leurs clients.
Puis, à l’issue de ces deux corrections, il peut encore subsister un écart résiduel. Cet écart est attribué au problème de sous-déclaration par les ménages de la valeur de leur patrimoine. Un calage est alors réalisé sur les données de comptabilité nationale par instrument en utilisant la méthode d’allocation proportionnelle. Par exemple, s’il y a x % d’écart entre l’agrégat de comptabilité nationale et les données agrégées de l’enquête, chaque ménage voit son patrimoine augmenter de x %. D’autres méthodes plus élaborées envisagées pour ce calage n’ont pas donné de résultats satisfaisants. Il a donc été choisi de retenir la plus simple.
Enfin, pour répondre à la demande des utilisateurs, il faut produire des données trimestrielles alors que les données d’enquête sont triennales. À ce stade, la méthode retenue est celle de l’interpolation linéaire par fractile. Si, pour un instrument donné, la part définie par les 20 % des ménages les moins riches augmente de deux points de pourcentage entre deux années d’enquête, il sera considéré que la part augmente à chaque trimestre de 2 divisé par le nombre de trimestres entre les deux points d’enquête. Les parts interpolées sont ensuite multipliées par les données de comptabilité nationale pour retrouver les montants en euros. L’extrapolation repose sur l’hypothèse que la part détenue par chaque fractile reste constante les années suivant la dernière année d’enquête.
Les premiers résultats
Le tableau ci-dessous montre l’effet de ces différentes corrections sur la distribution de l’enquête patrimoine. Dans l’enquête Histoire de vie et Patrimoine, la part des 1 % les plus riches est de 17,4 %. Elle passe à 24,6 % après la correction opérée sur le haut de la distribution et à 26,6 % après le calage final. De même, le patrimoine médian passe de 100 000€ à 150 000€ (tableau 1).
Tableau 1.
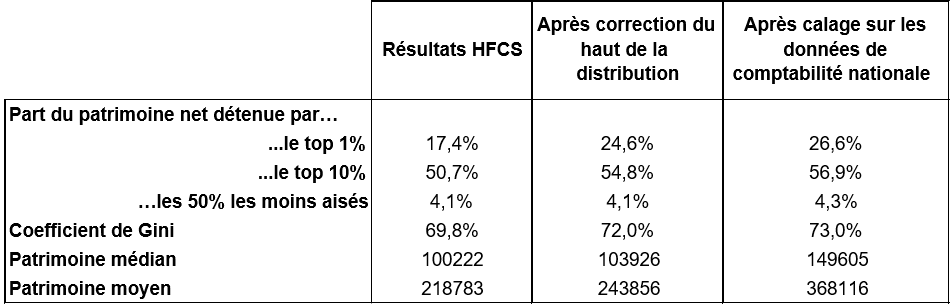
Source : HFCS 2017.
Les résultats de l’ESCB obtenus pour la France peuvent être comparés aux résultats obtenus par le World Inequality Lab selon une approche différente utilisant à la fois des données d’enquête et une estimation basée sur les données fiscales. Les résultats de l’ESCB montrent que la part de patrimoine détenue par les 10 % de ménages les plus riches s’élevait à 57 % au dernier trimestre 2020, en légère hausse depuis 2009, où elle était légèrement inférieure à 55 %. La part détenue par les 50 % les moins aisés est restée globalement stable, autour de 5 %. La part détenue par les 40 % de la classe moyenne a légèrement diminué entre 2009 et 2020, passant de 41 % à 39 % (graphique 2)
Ces résultats sont proches de ceux obtenus par le WIL, qui évalue la part détenue par les 10 % les plus riches à près de 60 % du patrimoine, avec une légère tendance à la hausse entre 2009 et 2020, la part détenue par les 50 % les moins aisés stable à 5 % et la part détenue par les 40 % de la classe moyenne à 36 % en 2020 contre 38 % en 2009.
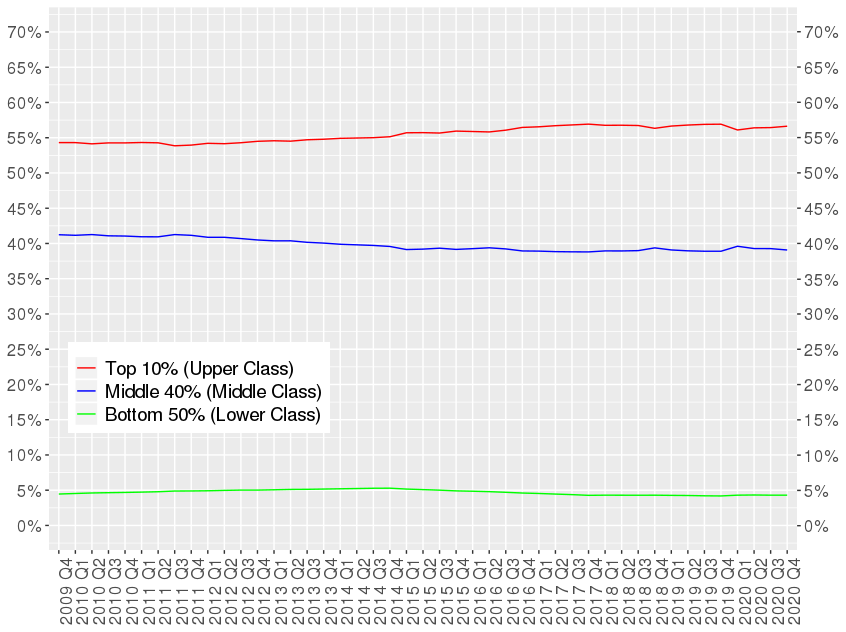
Source : Banque de France, données ESCB
Les futures améliorations
Au total, ces comptes distributionnels illustrent une utilisation possible et originale de l’enquête harmonisée européenne HFCS. Cette enquête est régie par un manuel de procédure commun à l’ensemble des pays qui définit de façon stricte les variables à fournir, les contrôles qualité, l’échantillonnage… En outre, le questionnaire couvre d’autres aspects que le revenu et le patrimoine : les questions concernent aussi la transmission d’héritages, la mobilité sociale et pour chacune des vagues triennales un module de questions ad hoc est ajouté : par exemple sur la vague 2020 qui sera publiée en mars 2023, des questions relatives à la pandémie ont été ajoutées. Enfin, un travail conséquent de mise en qualité des données a été réalisé depuis plus de 10 ans par le réseau. Au total cette enquête est un outil très riche qu’on peut décliner de multiples façons comme en témoigne l’élaboration de ces comptes distributionnels.
Ces derniers reposent sur une approche purement statistique qui s’appuie sur des corrections homogènes entre les pays et ne modifie pas (ou à la marge) les déclarations des enquêtés. Ils ont été mis à disposition des utilisateurs internes ESCB fin 2021. Le Comité Statistique de la BCE décidera (en fonction des retours utilisateurs, des améliorations réalisées par EG-DFA en 2022, etc.), sur la base du rapport final EG DFA qui sera remis fin 2022, de leur mise à disposition du public.
Ce premier travail pourrait être ensuite enrichi selon deux grands axes. Le premier consiste à mesurer la qualité des résultats obtenus par la méthode de l’ESCB à l’aide de données administratives, par exemple sur la composition du patrimoine des ménages, et à explorer des méthodes d’extrapolation alternatives. Le second porte sur l’enquête elle-même et vise à minimiser les corrections à apporter aux résultats de l’enquête. Une première solution consiste à augmenter la taille du sur-échantillon de ménages aisés pour mieux capturer le haut de la distribution. La deuxième réside dans la mobilisation de données administratives afin de compléter voire de remplacer les données individuelles pour certains instruments afin d’alléger la charge de l’enquête.
Mots clés : statistique, patrimoine, inégalités, revenus, enquêtes
[1] Expert Group Distributional Financial Accounts
[2] Le taux de couverture est égal au rapport entre l’agrégat issu de l’enquête (la somme des réponses des ménages enquêtés) sur l’agrégat de comptabilité nationale.
[3] cf annexe 2.a. Understanding household wealth: linking macro and micro data to produce distributional financial accounts (europa.eu).
[4] Même si dans le cas de la France, les hauts patrimoines sont sur-échantillonnés pour pallier cette sous-estimation.
Le scandale statistique des comptes de patrimoine en France a peu à voir avec la maltraitance de mouches de l’article ci-dessus et plus à voir avec la prédominance de pensions des agents publics ou sous statut en France. Alors que pour les méchants riches du secteur privé, les assurances vie et autres rares plans de pension sont pris en compte, la disponibilité à 50 ans ou 55 ans d’une retraite proche du dernier salaire pour les 30 années de retraite compte pour RIEN. Donc tous les millionnaires de la FP et de la RATP EDF SNCF sont des pauvres. Pourtant une retraite de 3500 EUR par mois pendant 30 ans, garantie, ca a une valeur.
De manière similaire, une créance sur un bailleur social d’un loyer 50% en dessous du marché pour deux ou trois générations (impossibilité d’expulser tant que l aieule est sur le bail, meme si elle est retournée au Mahgreb) compte pour RIEN. pourtant un sous-loyer de plusieurs centaines d euros sur 3 generations, ca a une valeur patrimoniale