
Cet article est une synthèse du mémoire d’actuariat « Étude et implémentation de techniques d’analyse de sensibilité dans les modèles de tarification Non-Vie. Application à la tarification à l’adresse », qui a reçu le Prix des jeunes actuaires 2021 décerné par SCOR, consacré par Silvia Bucci à l’apport du Machine Learning aux modèles de tarification en assurance. Il montre que ces nouvelles techniques permettent un enrichissement des stratégies tarifaires mises en œuvre par les assureurs, même si la sophistication des techniques ne réduit pas l’importance d’une intervention humaine dans l’arbitrage entre performance, transparence et éthique.
L’utilisation des modèles plus sophistiqués, connus sous le nom de modèles de Machine Learning, n’est pas nouvelle en assurance.
Dans le processus de tarification, ces techniques sont exploitées afin d’atteindre une connaissance très fine du risque et de la clientèle, dans la sélection des critères tarifaires, leur segmentation en classes de risques homogènes, dans la création de nouvelles variables, …
Du fait que ces techniques reposent sur des hypothèses moins strictes sur la distribution des données par rapport aux méthodes « traditionnelles » telles que les modèles linéaires généralisés (GLM), le Machine Learning interprète mieux que les GLMs la complexité de la donnée, complexité qui peut se manifester sous plusieurs formes : le nombre de variables en entrée, la qualité de ces variables et leur lien avec la fréquence et le coût moyen des sinistres.
Toutefois, le rôle de ces techniques est encore marginal et la plupart des assureurs continuent à utiliser les GLMs comme modèle de tarification principale, en faisant allusion au manque d’interprétabilité[1](phénomène connu comme Black Box ou boite noire), à la complexité de la mise en place et au risque de personnalisation extrême du risque[2] que les modèles sophistiqués pourraient engendrer dans le processus de tarification.
Les interactions statistiques : une expression de la complexité de la donnée
Dans le cadre de ce mémoire, l’objectif est d’identifier la complexité de modèles black box à l’aide de techniques d’interprétabilité des modèles et d’analyse de sensibilité et de l’intégrer dans un processus de tarification traditionnel, afin de garder une structure simple et intuitive, tout en bénéficiant du pouvoir prédictif des modèles Black Box.
Nous avons restreint la recherche de la complexité des modèles sophistiqués aux interactions statistiques entre deux variables, c’est-à-dire l’impact simultané de deux variables sur la sinistralité. Ainsi, il suffira d’ajouter des termes croisés à l’équation tarifaire du modèle de départ.
Les modèles de Machine Learning incluraient déjà les interactions les plus fortes parmi les variables, mais celles-ci ne sont pas transparentes à cause de l’effet boîte noire.
Les indices de Sobol et les indices de SHAP appartenant aux domaines de l’analyse de sensibilité et du plus récent Explainable Artificial Intelligence (XAI) sont les outils choisis pour « ouvrir » les modèles Black Box.
Cette méthodologie a été appliquée au produit Multirisque habitation (MRH) de l’assurance du particulier Smart Home Pricing pour la garantie Dégâts des eaux. Sa particularité est que la tarification utilise des données météorologiques, économiques, climatiques, démographiques à mailles fines, jusqu’à l’adresse et même au bâtiment. Parmi les variables innovantes, nous utiliserons par exemple la présence de gel, le nombre de jours orageux ou le nombre d’artisans dans la commune.
Etapes de l’étude
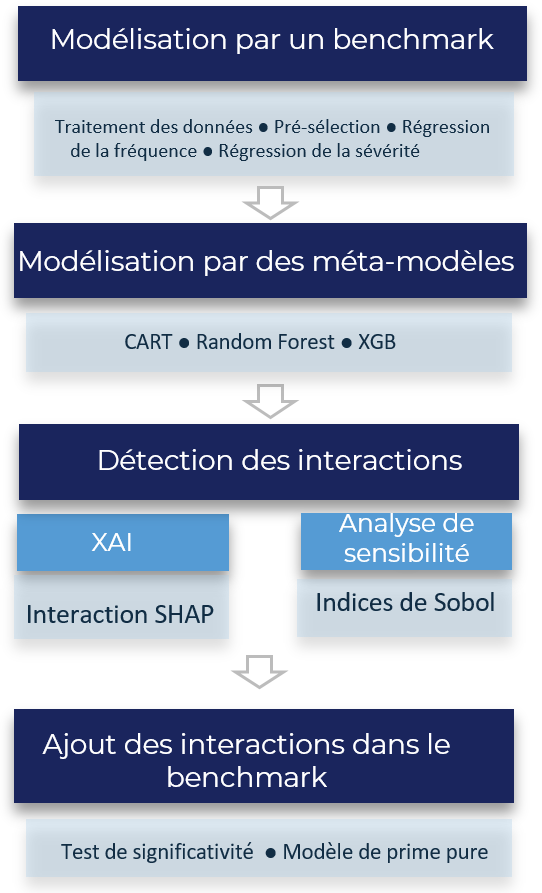 La force de la méthodologie d’étude que nous proposons est qu’elle peut s’appliquer à n’importe quel type de modèle.
La force de la méthodologie d’étude que nous proposons est qu’elle peut s’appliquer à n’importe quel type de modèle.
- Dans un premier temps, nous avons modélisé la fréquence et la sévérité des sinistres à partir des données de la tarification à l’adresse. Le modèle traditionnel GLM, appelé Benchmark sera celui auquel on ajoutera les interactions.
- Ensuite nous avons construit trois modèles de Machine Learning, un arbre de régression, une forêt aléatoire et un Extreme gradient boosting (xgboost) : ils ne seront pas utilisés en tant que modèles de tarification, mais comme modèles complexes. On supposera que leur complexité est manifestée par l’introduction d’interactions dans leur structure prédictive.
- En deuxième lieu, à l’aide de l’analyse de sensibilité (indices de Sobol) et de XAI (indices SHAP), nous avons détecté les interactions des modèles complexes construits à l’étape précédente.
L’arbre de régression est interprétable par construction : l’algorithme utilisé construit une suite de partitions du portefeuille de plus en plus fines ; à chaque étape une variable et un seuil sont choisis et la population est divisée en deux classes. Les classes de la dernière partition sont appelées nœuds-fils et elles représentent les prédictions associées à chaque profil de risque.
Les interactions introduites par l’arbre de régression sont lisibles par construction de l’arbre : chaque diramation introduit une variable qui interagit avec les variables des diramations précédentes. - Enfin, les interactions seront ajoutées au modèle de Benchmark : les interactions SHAP seront ajoutées en tant que fonctions indicatrices, car elles segmentent naturellement le domaine de définition de deux variables ; celles de Sobol, étendues à tout le domaine de définition, seront ajoutées comme termes polynomiaux du second degré.
GLM : un modèle interprétable, mais peu complexe
Plus de 80 % du marché de l’assurance utilise un modèle linéaire généralisé pour prédire la prime pure à partir d’environ 20 variables explicatives.
En tant que sophistication des modèles linéaires dont ils héritent une structure linéaire, il est possible de décomposer la prédiction d’un GLM dans la somme des effets de chacune des variables du modèle :
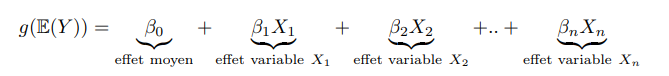
En particulier, il est possible d’obtenir la prime pure très simplement à partir d’une calculette tarifaire. C’est pour cela qu’aujourd’hui les GMS, introduits par Nelder et Wedderburn (1972), sont la norme de l’industrie de l’assurance pour développer des modèles analytiques de tarification.
La détection des interactions par des méthodes innovantes a été motivée par une limite du GLM : ce modèle, malgré son haut degré d’interprétabilité, n’inclut pas des termes de degré supérieur (des polynômes multivariés), c’est-à-dire qu’il manque de la complexité engendrée par l’effet croisé de deux (ou plusieurs) variables.
Selon les hypothèses du modèle, l’effet de chaque variable indépendante est constant quelle que soit la valeur prise par les autres variables indépendantes.
Toutefois, l’effet des variables peut évoluer en fonction des valeurs prises par l’une des autres variables indépendantes introduite dans le modèle.
On dit dans ce cas qu’il y a une interaction entre ces deux variables. L’effet de l’âge sur le coût d’un sinistre n’est pas constant par exemple, mais il dépend de la valeur du logement.
Méthode innovante de détection d’interactions
La pratique la plus utilisée pour se rapprocher de la performance des modèles de Machine Learning est l’ajout manuel de termes croisés ou d’interaction (i.e. l’âge et la zone de résidence) parmi les variables explicatives dans l’équation tarifaire : on complète cet ajout à l’aide d’un test de significativité, qui permet d’évaluer si l’on doit garder l’interaction dans le modèle.
Il est difficile de mettre en place cette pratique lorsqu’on souhaite utiliser des données plus complexes du fait de leur granularité (par exemple à la maille adresse) ou de leur caractère innovant et sectoriel.
Pour y remédier, nous avons mis en place une méthodologie de détection d’interactions des modèles de Machine Learning, dans une vision plutôt inclusive et collaborative entre les modèles sophistiqués et les GLMs.
Ainsi, en supposant que l’interaction statistique est une manifestation de la complexité des modèles black box, l’optimisation d’un GLM simple à l’aide des interactions bénéficie des gains opérationnels des modèles d’apprentissage automatique.
Les outils de détection employés, à savoir les indices de Sobol et indices de SHAP sont les clés de relecture des modèles prédictifs, puisqu’ils visualisent et quantifient les impacts des variables d’entrée sur la sortie selon un « juste » partage.
Ces deux techniques sont complémentaires, car l’une intervient globalement, en quantifiant les interactions sur tout un portefeuille de client, alors que l’autre est locale, c’est-à-dire quantifie l’impact de l’interaction client par client.
Au lieu de tester la significativité de l’ajout de chaque terme à l’équation tarifaire, nous avons ainsi préconisé une autre approche, introduisant des modèles qui utilisent intrinsèquement des interactions.
Cette méthode s’appuie sur la décomposition d’une quantité d’intérêt : la variance du modèle ou la valeur prédite.
- La variance du modèle est décomposée en somme d’autant d’éléments que de groupes possibles de variables (par exemple le groupe « âge et valeur de l’habitation »).
Chaque terme de cette somme, normalisé par la variance totale, est appelé indice de Sobol d’ordre k et il représente la partie de la variance induite par un groupe de k variables.
On distinguera les indices d’ordre 1, induits par une seule variable (par exemple l’indice d’ordre 1 de l’âge ou l’indice d’ordre 1 de la valeur de l’habitation) et les indices d’ordre supérieur à 1 qui sont induits par plusieurs variables simultanément. Ces derniers indices nous informent en particulier de l’impact des interactions sur la variance d’un modèle.
La force de ces indices réside dans le fait que leur somme est égale à 1, ils sont donc très simples à interpréter : plus un indice est proche de 1, plus le groupe de variables considéré sera important vis-à-vis de la variance.
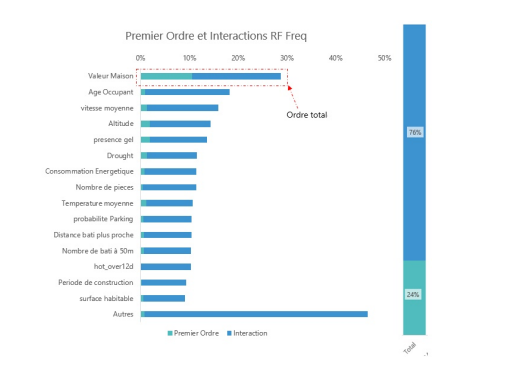 Considérons un des modèles calibrés qui prédit la fréquence des sinistres, une forêt aléatoire (RF). Les indices d’ordre 1, c’est-à-dire les indices qui quantifient l’impact de l’ajout des variables dans le modèle singulièrement, expliquent 24 % de la variance totale, alors que les interactions contribuent à 76 %. La variable la plus importante au sens de la décomposition de Sobol est la valeur de l’habitation qui à elle seule explique environ 30 % de la variance.
Considérons un des modèles calibrés qui prédit la fréquence des sinistres, une forêt aléatoire (RF). Les indices d’ordre 1, c’est-à-dire les indices qui quantifient l’impact de l’ajout des variables dans le modèle singulièrement, expliquent 24 % de la variance totale, alors que les interactions contribuent à 76 %. La variable la plus importante au sens de la décomposition de Sobol est la valeur de l’habitation qui à elle seule explique environ 30 % de la variance.
Les interactions entre deux variables, les indices de Sobol d’ordre 2, ont été estimées et celles importantes (supérieures à 1 % ou 2 % de la variance, selon le modèle) ont été intégrées dans le modèle de Benchmark.
Nous nous sommes restreints aux indices du deuxième ordre pour éviter le sur-apprentissage et pour limiter le coût algorithmique.
- La décomposition de la valeur prédite dérive de la théorie des jeux et c’est une notion locale, qui s’interprète individu par individu.
Chaque client, selon la prédiction de sa sinistralité, se positionne au-dessus ou en dessous de la moyenne du portefeuille. Le positionnement dépend de la contribution de chacune de ses caractéristiques, appelée valeur SHAP (SHapley Additive exPlanations).
La valeur prédite, notée f(x) pour un client x , peut alors se décomposer de la façon suivante :
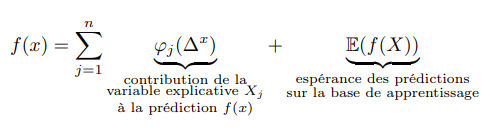
 Dans ce cadre, les interactions sont la partie de la valeur SHAP due au croisement de deux variables.
Dans ce cadre, les interactions sont la partie de la valeur SHAP due au croisement de deux variables.
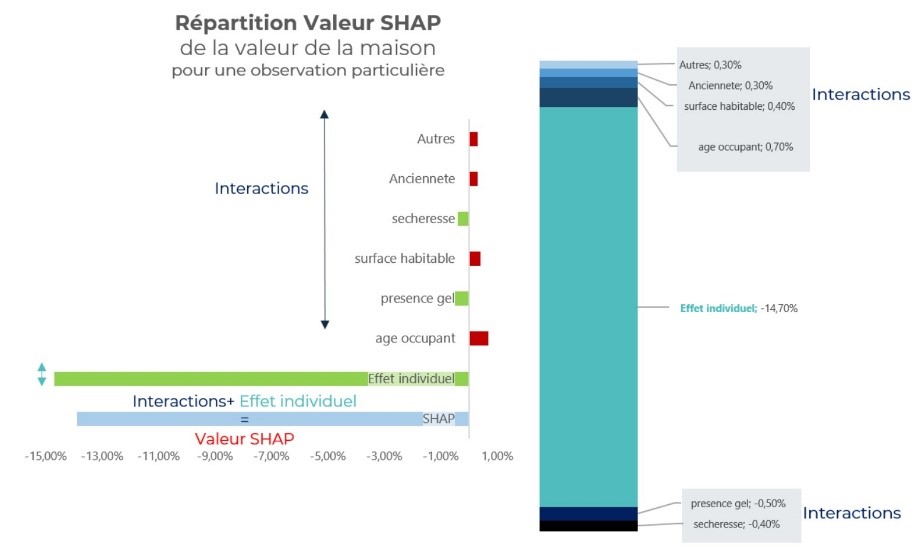
Considérons le modèle de fréquence des sinistres xgboost et un individu du portefeuille dont le niveau SHAP de la valeur de l’habitation est de -13.8 %.
Cela signifie que l’impact de la valeur de l’habitation place l’individu en dessous de la prédiction moyenne (car le signe est négatif).
Il est possible d’isoler dans la valeur SHAP la contribution des interactions : les interactions de la valeur de la maison avec l’âge, l’ancienneté et la surface ont un signe positif et elles sont responsables de la hausse du nombre de sinistres.
Vers une vision inclusive et collaborative ?
Dans le cadre de cette étude, une analyse de sensibilité a été menée sur des données relatives à l’adresse pour améliorer le modèle de tarification de la garantie « Dégâts des eaux ». Elle a permis d’ajouter de la complexité tout en gardant une structure analytique, transparente et interprétable qui s’intègre parfaitement au processus de tarification traditionnel des organismes d’assurance.
Afin de respecter ces critères, nous avons reconduit le problème d’optimisation tarifaire au problème de détection et d’intégration des interactions parmi les variables, l’interaction étant une expression de la complexité du modèle. Nous avons d’abord détecté les interactions des modèles plus sophistiqués, dits de type boîte noire à cause de leur structure prédictive non accessible, en nous appuyant sur des concepts de la théorie de jeux et de l’analyse de sensibilité selon Sobol.
D’un côté, les indices de Sobol de l’ordre deux nous informent de la part de la variance totale due à chacune des interactions, de l’autre les indices d’interaction SHAP déterminent dans quelle direction l’interaction a un impact sur la prédiction (si elle est à la hausse ou à la baisse à cause de l’interaction) et selon quelle intensité.
Ensuite nous avons intégré les interactions détectées localement (SHAP) et globalement (Sobol) en ajoutant des termes polynomiaux dans le modèle GLM de départ.
Ces termes améliorent le modèle GLM simple selon des métriques d’évaluation habituelles (MSE, RMSE, MAE, Q2, Gini, déviance, AIC) avec un gain entre 0.03 % et 17 %.
Plus généralement, cette méthodologie de détection ne se limite pas à l’optimisation tarifaire : son caractère agnostique permet de l’appliquer à n’importe quel modèle complexe ou non. De plus, ce parcours nous a fait expérimenter une nouvelle approche portant sur la collaboration du Machine Learning et des modèles linéaires généralisés (GLM) : dans la littérature actuarielle, on a tendance à comparer la performance des modèles plus complexes au GLM classique, ou à se servir de l’un ou de l’autre type de modèle pour deux études séparées.
Par ailleurs, la perception du risque géographique obtenue par les modèles plus complexes et par les données à maille fine (à l’adresse et au bâtiment) est plus précise.
Du point de vue de la stratégie d’entreprise, capter les interactions dans un modèle, comme manifestation de la complexité de la donnée sous-jacente, aide le processus de revalorisation tarifaire et permettrait notamment de créer une formule tarifaire personnalisée selon un profil spécifique (étudiant, propriétaire dans un grand centre, …).
Que ce soit en Vie ou Non-Vie, dans les lignes commerciales ou dans les produits du particulier, l’utilisation du Machine Learning a une forte valeur ajoutée sur le placement de l’assureur dans le marché concurrentiel.
Toutefois, bien que ces techniques permettent de mieux évaluer la prime de risque selon les caractéristiques du client et d’aider à construire de nouvelles stratégies tarifaires, elles ne remplaceront pas l’assureur dans son rôle d’arbitre entre performance, transparence et éthique.
Mots-clés : Analyse de sensibilité – XAI – Interactions en assurance Non-Vie – Indice de Sobol – SHAP – MRH Multirisques Habitation – Tarification à l’adresse
Bibliographie
Mémoire d’actuariat : https://foundation.scor.com/sites/default/files/2022-01/Silvia_Bucci_Memoire_ia-light.pdf
[1] Les modèles de Machine Learning, tels que Random Forest, xgboost, Réseaux de neurones ne sont pas interprétables et la loi confère aux individus le droit à une explication de la logique qui sous-tend la décision (RGPD art.22, RGPD Raison 71), ce qui signifie que les modèles de tarification doivent être transparents et faciles à communiquer à tous. Les multiplicateurs (qui dérivent des coefficients de régression linéaire) identifient l’effet que chacune des variables a indépendamment des autres sur la sinistralité.
Or, le manque d’interprétabilité rend impossible l’identification de tous les impacts dans un modèle plus sophistiqué.
[2] L’utilisation du Machine Learning dans la tarification peut conduire à une « personnalisation du risque » extrême ou à une discrimination, au détriment de la mutualisation des risques, par exemple sous la forme de primes extrêmement élevées.

A l’issue d’une formation mathématique à l’université de Bologne en Italie, Silvia a intégré le Master d’Actuariat de l’Université Gustave Eiffel (ancienne UPEM) en alternance dans le pôle de tarification P&C de CHUBB. Elle a ensuite poursuivi son cursus à l’ENSAE pour l’obtention du titre d’actuaire en se dédiant aux sujets de recherche et développement dans la practice P&C du cabinet Addactis. En septembre 2021 elle a rejoint l’équipe internationale Property Pricing& Analytics de AXA XL.
Silvia a reçu le Prix SCOR des jeunes actuaires 2021 pour ce mémoire.