
Les nouvelles opportunités au sens général naissent lorsqu’il existe de nouveaux territoires à explorer.
Depuis des millénaires, les opportunités sont nées suite à la découverte de territoires et de leur exploration, que ce soit au 15è siècle avec la découverte de l’Amérique du Nord ou actuellement avec les espaces digitaux qui s’étendent à une vitesse exponentielle. Ainsi, se développe l’économie du « Big Data », intégrant par exemple des sources de données issues des réseaux sociaux, des télécoms, des satellites d’observation, des objets connectés, et bien d’autres.
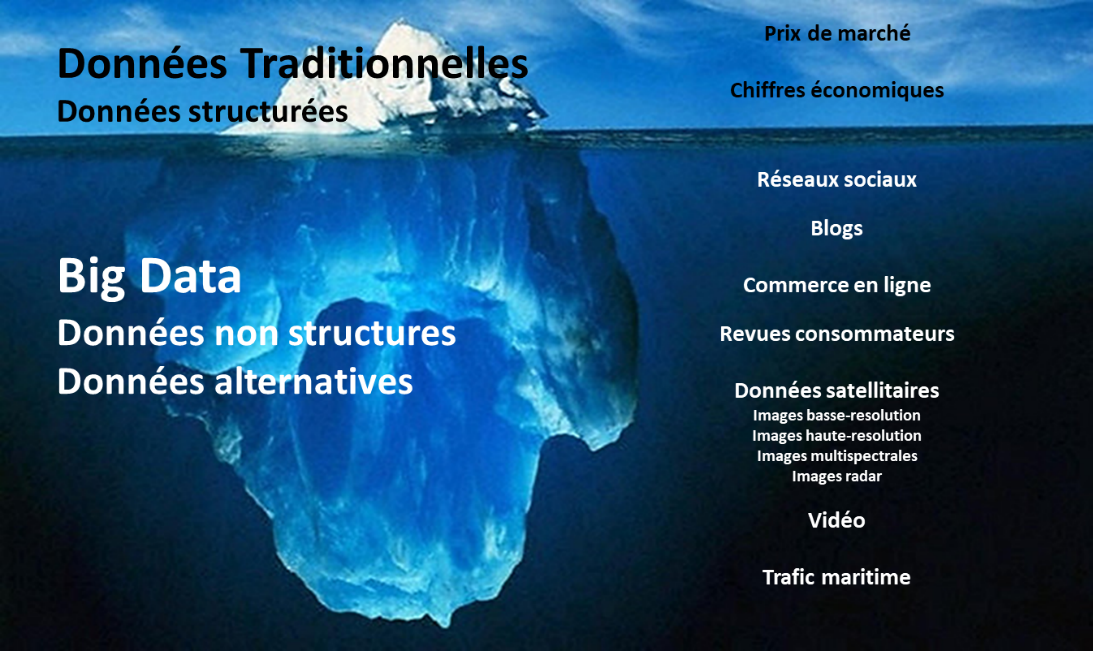
Le Big Data : de nouveaux territoires à exploiter pour créer de la valeur
L’émergence de ces données massives ouvre par conséquent de nouveaux territoires à explorer en analyse des données. Associée aux nouvelles technologies à l’origine d’une augmentation considérable des puissances de calcul, l’exploitation de ces nouvelles données est génératrice de valeur, d’opportunités, notamment dans le domaine de l’économie et de la finance.
Pour se préparer à créer de nouveaux services et de nouvelles applications économiques et financières, tant à partir de ces nouvelles sources de données que des données existantes, les étudiants de l’ENSAE sont extrêmement bien positionnés pour les prochaines décennies.
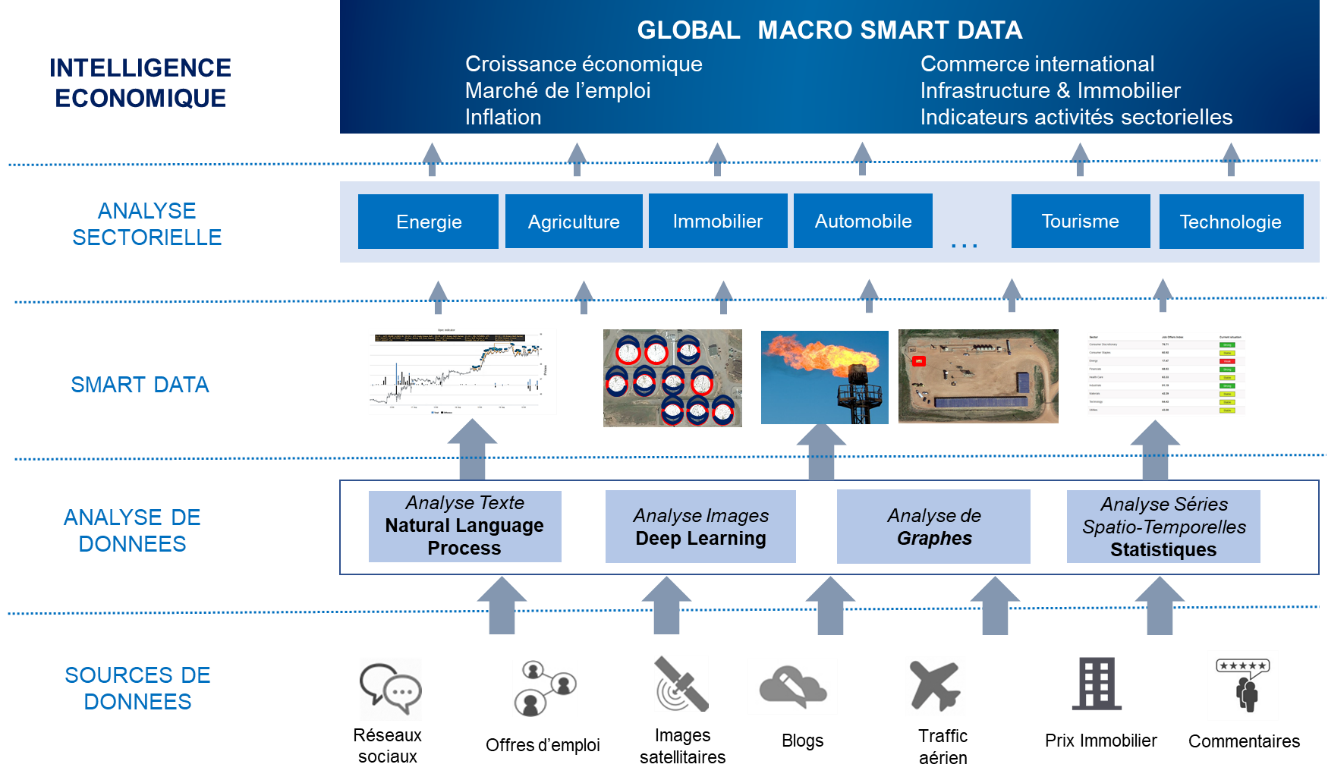
QuantCube Technology a relevé ce défi en se spécialisant en Intelligence Artificielle pour les prévisions macroéconomiques et financières à partir de l’analyse du Big Data, c’est-à-dire en estimant en temps réel les grandes variables macroéconomiques telles que la croissance économique, l’inflation, le marché de l’emploi et des informations sectorielles. Pour cela, de multiples sources de données structurées et non structurées sont analysées puis croisées, la sélection des sources de données étant le résultat d’une analyse fondamentale découlant d’une compréhension profonde de l’économie de chacun des pays étudiés.
La mesure de l’économie en temps réel à partir du Big Data
 L’imagerie satellite
L’imagerie satellite
Ces dernières années, au sein de QuantCube, l’équipe de Data Scientists dédiée à l’analyse d’images a développé une nouvelle génération d’indicateurs macroéconomiques intitulée ‘Urban Space Series’ à partir d’images satellites, ceci avec le soutien technique et financier du Centre National des Etudes Spatiales (CNES) et de l’Agence Spatiale Européenne (ESA).
Concrètement, il est désormais possible d’estimer la croissance économique urbaine à partir des données satellitaires, telles que celles de Sentinel-2, qui fournit tous les cinq jours des images d’une largeur au sol de 290 km et d’une résolution de 10 à 60 m selon les bandes spectrales allant du visible au moyen infrarouge.
Cette série d’indicateurs permet de mesurer la croissance économique urbaine de manière systématique, contournant les différentes méthodologies relatives au calcul de la croissance économique en fonction des pays. Pour cela, à partir d’une image Sentinel-2, il est possible d’extraire les zones urbaines et de classifier le terrain en 18 classes différentes (zone urbaine, résidentielle, commerciale, espace vert, zone industrielle, forêt, champs, etc.).
L’analyse des images Sentinel-2 en temps réel, en fonction des taux de revisite de la zone géographique concernée, permet alors de mesurer les aires urbaines de façon systématique et homogène, et ainsi de comparer les formes des différentes villes et de suivre leur croissance en temps réel. Cette analyse d’images offre la possibilité aux utilisateurs d’obtenir les formes des aires urbaines des villes sélectionnées ainsi que plusieurs autres indicateurs comme leur aire ou périmètre.
Comparée à d’autres études faites pour calculer cet indicateur, l’utilisation d’une unique source de données – Sentinel-2 – avec un même algorithme permet de comparer aisément les croissances économiques urbaines entre villes et pays.
Exemple de modèle de Machine Learning pour l’analyse d’images – Modèle Tiramisu
Afin d’estimer l’aire urbaine ainsi que l’identification des surfaces des villes, un modèle de segmentation d’image est utilisé pour classifier chaque pixel de l’image. Dans ce cadre-là, le modèle Tiramisu a été implémenté. L’objectif de ce modèle est d’exploiter l’architecture DensetNet, tout en compensant l’augmentation du nombre de fonctionnalités.
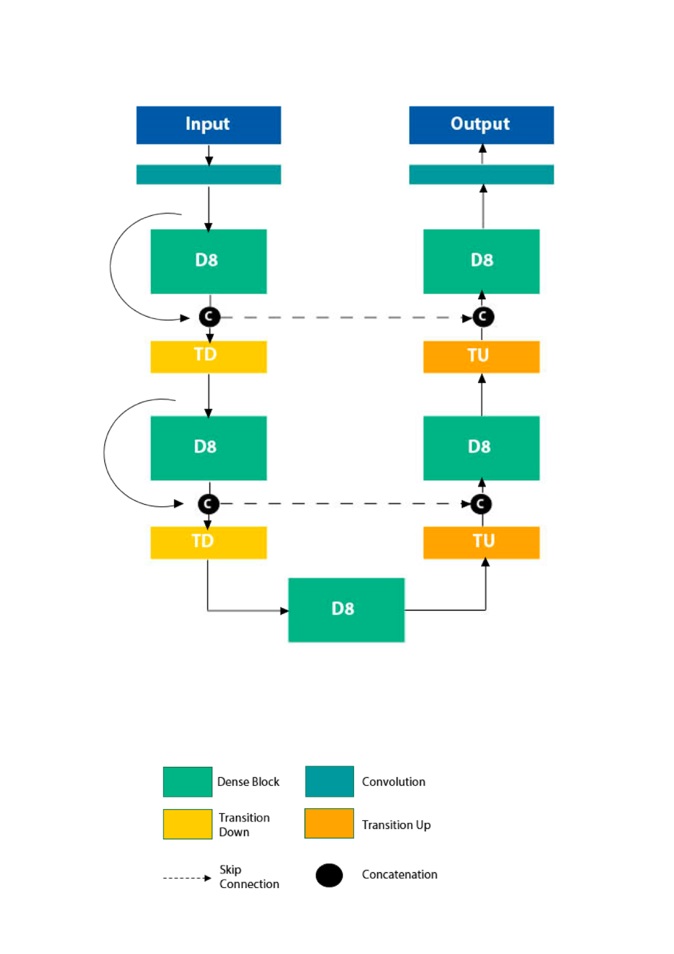
En ce qui concerne le modèle Tiramisu, l’architecture du réseau ci-contre est composée d’un downsampling path (responsable de l’extraction de caractéristiques à différentes échelles spatiales) qui commence avec une première convolution, puis une nouvelle carte de fonctionnalités est créée au sein de chaque dense block. Un dense block est composé de plusieurs couches permettant d’extraire des cartes de caractéristiques, la sortie du dense block étant la concaténation des sorties de toutes les couches du block. L’image en sortie passe donc à travers la première couche pour créer un nombre k de cartes de fonctionnalités qui sont concaténées à l’entrée de la couche suivante, et ainsi de suite. Entre chaque dense block, la résolution de l’image diminue et le nombre de versions de l’image représentant une fonctionnalité augmente. La principale caractéristique de ce modèle DenseNet est qu’il enregistre les sorties de chaque couche du modèle. Après chaque dense block, l’augmentation du nombre de fonctionnalités est compensée par une réduction de la résolution de l’image.
Par la suite, la résolution de l’image est comparée à l’originale par le upsampling path (entraîner pour retrouver la résolution originale de l’image sur l’output du modèle) en s’appuyant sur les informations spatiales de la couche miroir du réseau à l’aide de skip connexion (connections entre le downsampling path et le upsampling path permettant de récupérer les hautes fréquences de l’image originale) afin de retrouver le même niveau de détail que l’image originale. Finalement, la sortie du réseau est une image de la même résolution que celle de l’entrée, la couleur de chaque pixel indiquant la classe de ce même pixel par rapport à l’image d’origine.
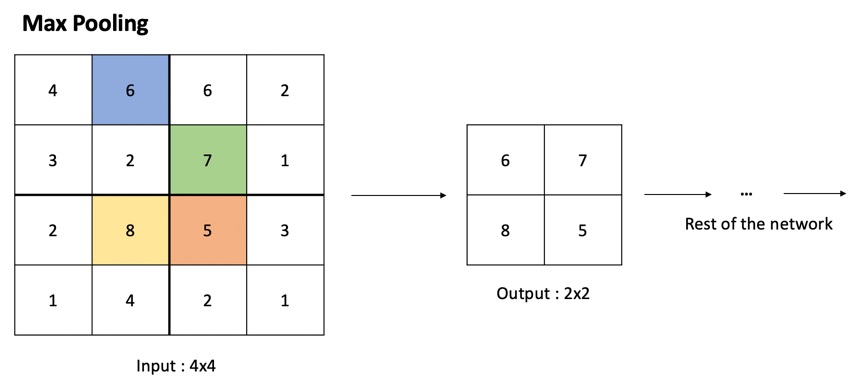
On observe d’une part que la croissance du nombre de fonctionnalités dans le « down-sampling path » est compensée par la réduction de la résolution spatiale après l’opération de MaxPooling. Cette opération est un concept important des réseaux de neurones convolutifs permettant un sous-échantillonnage de l’image. En effet, le pooling réduit la taille spatiale d’une image intermédiaire, réduisant ainsi la quantité de paramètres et de calcul dans le réseau, permettant aussi d’extraire des fonctionnalités sur des échelles spatiales plus grandes.
D’autre part, dans le « up-sampling path », les transitions « up » consistent à suréchantillonner les cartes de fonctionnalités, augmentant la résolution de l’image. Pour réintroduire les hautes fréquences perdues dans le MaxPooling de la première moitié du réseau, on utilise l’information spatiale des images de la première moitié de réseau (des « skip connections »).
A un niveau plus granulaire, l’objectif est désormais d’établir une classification plus fine en travaillant avec des images multi-échelle (jusqu’à 50 cm de résolution) pour classifier les bâtiments et les installations dans un milieu extra-urbain. Pour cela, Quantcube Technology a intégré un ensemble de plus d’un million d’images provenant de plus de 200 pays dans des villes de densité de construction moyenne. Cette étape a permis de classifier les bâtiments en 63 catégories différentes (hôpital, parking, station essence, site en construction, etc.) et donc d’obtenir une carte plus détaillée des villes étudiées. Une application directe est la caractérisation de la détection de changement à partir de la carte de fonctionnalité des bâtiments.
Tout d’abord, l’étude de la croissance urbaine réalisée à partir des images à 10 mètres de résolution a permis de détecter les nouvelles constructions et démolitions dans une ville, et de caractériser ce changement en 13 différentes classes (résidentielle, commerciale, etc.), avant d’utiliser des images haute-résolution pour créer 63 classes. Pour cette dernière étape, une fonctionnalité a été attribuée à chacun des nouveaux bâtiments : construction d’un hôpital, d’un commissariat de police et même d’une école.
Par la suite, Quantcube Technology étudie également des zones non urbaines à partir de l’analyse des images hyperspectrales, pour caractériser l’état de la couverture naturelle des sols : terre, cultures, forêts, etc.
Prenons l’exemple de la ville de Reims pour calculer sa superficie urbaine. Nous pouvons récupérer l’image spectrale de la ville prise par le satellite Sentinel-2. A partir de cette image nous pouvons créer différents indicateurs. Dans un premier temps des indices de végétation sont calculés. Ces derniers nous permettent notamment de caractériser les zones non urbaines de la ville et l’état de la couverture naturelle des sols. Dans un second temps, comme détaillé ci-dessous, les zones urbaines de la ville sont étudiées en calculant notamment la superficie de la ville. En comparant ces indicateurs avec ceux calculés à des dates antérieures, il est alors possible de suivre la croissance urbaine de la ville de Reims.
Input : Image Spectrale de Reims, France

Output : Indice de végétation et Superficie urbaine
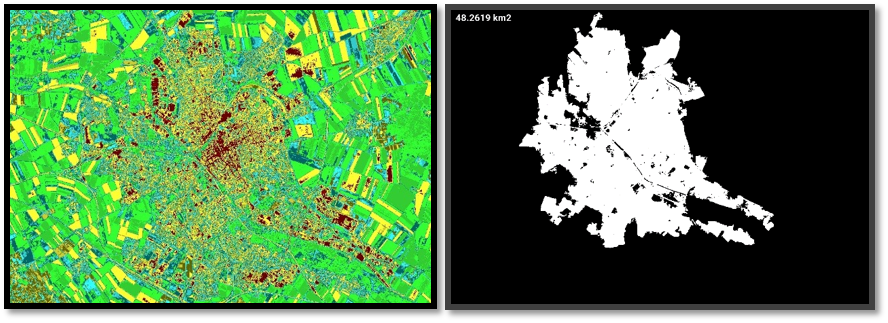 https://business.esa.int/projects/urban-space-series
https://business.esa.int/projects/urban-space-series
En conclusion, afin de créer de nouvelles applications financières et économiques s’appuyant sur l’Intelligence Artificielle, il est nécessaire de combiner de la technologie, des algorithmes avancés d’analyse, mais aussi des experts des différents métiers – économie, finance de marché, finance d’entreprise –. Avec un volume exponentiel de données provenant de multiples sources et des puissances de calcul accessibles à tous, il est possible de créer une multitude de nouvelles applications apportant un regard nouveau sur l’économie ainsi que dans bien d’autres secteurs.
Tous mes remerciements aux anciens élèves de l’ENSAE qui ont fortement contribué au développement de la société à tous les niveaux : lors de la création de la société, pour son financement et dans son fonctionnement.
- Special edition on the US election - 23 octobre 2020
- Comment saisir de nouvelles opportunités avec l’IA en Economie et en Finance ? - 3 avril 2019
Commentaires récents