
En 2000, dans le cadre de l’ouverture des marchés européens de l’électricité engagée en Grande-Bretagne à la fin des années 1980, la France a créé Réseau Transport d’Electricité (RTE) qui détient en France continentale le monopole du transport d’électricité et la responsabilité de l’équilibre offre-demande d’électricité au jour le jour. La production et la commercialisation d’électricité sont ouvertes à la concurrence. La mise en place des marchés de gros de l’électricité et des mécanismes de Responsable d’Equilibre (qui assurent l’équilibre offre / demande sur leur périmètre) par RTE permet l’émergence de nombreux acteurs propriétaires ou non d’actifs de production. EDF est l’un d’entre eux, elle dispose pour assurer son équilibre de l’essentiel des moyens de production pilotables installés en France et doit servir une grande partie de la clientèle finale ; au sein d’EDF, la DOAAT (Direction Optimisation Amont/Aval & Trading) a en charge la gestion du périmètre d’équilibre d’EDF.
La DOAAT assure ainsi l’équilibre physique entre l’offre et la demande d’électricité au périmètre d’EDF au meilleur coût et en minimisant les risques physiques et financiers. L’activité repose sur de nombreux modèles statistiques permettant de réaliser des prévisions de variables pertinentes (prix des combustibles, consommation d’électricité, production éolienne, apport hydraulique, température de l’air et de l’eau…) et des optimisations nécessaires au pilotage d’un parc de production d’électricité de grande taille. Contrairement à d’autres énergéticiens, EDF doit gérer de nombreux stocks, ce qui lui impose quotidiennement de faire le choix entre une utilisation immédiate du stock ou sa préservation pour une utilisation future mieux valorisée. Déterminer cette valeur nécessite une vision anticipée des données relatives à la capacité de production (offre) et aux besoins de consommation (demande) sur un horizon de 4 à 5 ans. Les différentes composantes du système électrique sont soumises à des aléas et à des fondamentaux qui, au fil des années, ont nécessité des modélisations et des outils de prévision de plus en plus sophistiqués. A titre d’exemple, la demande d’électricité à satisfaire par EDF ne dépend plus seulement de la croissance économique, du développement des usages de l’électricité et de la température, elle doit prendre en compte le développement de la concurrence, les prix sur les marchés de gros qui eux-mêmes sont fortement liés à la situation sur la plaque électrique européenne avec en particulier l’impact important des productions éoliennes et solaires.
Pour élaborer chaque jour le programme de fonctionnement des usines afin d’assurer 24h sur 24 l’équilibre entre l’offre et la demande d’électricité d’EDF au moindre coût, il est ainsi nécessaire de disposer d’une panoplie complète d’outils qui couplent programmation dynamique stochastique à la prévision fine de la consommation et de la production des énergies nouvelles et renouvelables (ENR) comme l’éolien ou le solaire.
L’électricité ne se stockant pas, la qualité de la prévision des besoins à satisfaire et des moyens disponibles pour y parvenir est au cœur de nos enjeux. Pour ce faire, nous avons développé des expertises multiples dans la collecte et le traitement des données centrées sur le marché de l’électricité. Nous pouvons ainsi :
- Challenger en permanence nos méthodes via les nombreux outils d’IA (mélange de prédicteurs, stacking, Maching Learning automatisé) ;
- Etre à la recherche de nouvelles méthodologies (reinforcement learning), au sein d’un collectif (lors de compétitions internes et de projets en collaboration avec R&D) ;
- Collecter toujours plus de données dans le « lac de données » via les sources de données publiques et opendata pour enrichir les jeux d’apprentissage ;
- Garantir toujours plus de performance des outils qui doivent rester à l’optimum dans le temps dans un contexte d’évolution rapide : évolutions du contexte réglementaire, aléas climatiques impactant les conditions aux limites, qualité de données, extension de la quantité et de la variété des données.
La sûreté opérationnelle d’exploitation de nos modèles est devenue également un enjeu majeur au fil de la complexification du marché de l’électricité. La multiplication des données et des algorithmes a rendu nécessaire le développement d’outils puissants et innovants de détection d’anomalies.
Trois cas d’usage étudiés puis mis en exploitation à EDF sont détaillés dans cet article, illustrant ainsi la plus-value des innovations statistiques au service des enjeux de l’équilibre offre-demande.
Cas d’usage 1 : Le machine learning au service de la prévision ENR
Il existe depuis longtemps des modèles de prévisions de production éolienne et hydraulique produite au fil de l’eau par des usines dépendant du débit des fleuves. Ces deux sources d’énergie sont règlementairement injectées en priorité sur le réseau, et prennent une part de plus en plus importante dans le système électrique. Il est indispensable de toujours mieux les prévoir. C’est dans ce contexte que nous avons testé des méthodes de machine learning.
La production éolienne présente la simplicité de s’expliquer par les prévisions de vent, encore faut-il imaginer comment modéliser un parc sur le territoire complet, avec plus de 1400 sites de productions répartis sur tout le territoire. Une façon de voir le problème est de faire une « clusterisation » du parc d’après sa courbe de charge ; c’est-à-dire rassembler les séries chronologiques qui se comportent de façon similaire. Nous avons choisi une méthode de K-médoïdes qui a permis d’identifier 8 clusters qui suffisaient à segmenter la production du parc français.
Répartition géographique des 8 clusters
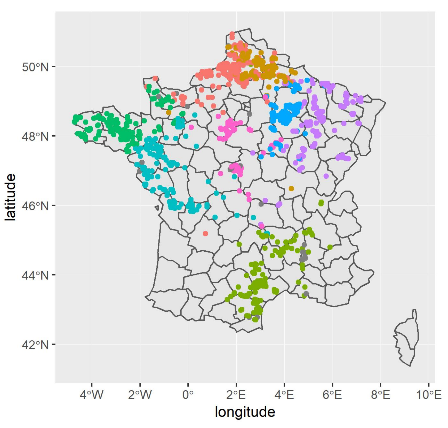
Il faut alors identifier les principaux points de mesure des prévisions de vent de Météo France et modéliser chacun de ces 8 clusters avec des méthodes d’apprentissage. C’est donc plusieurs méthodes de machine learning qui ont été testées : XGBoost, Random Forest, GAM, etc.
Elles sont ensuite optimisées pour ne garder finalement qu’un unique modèle, une liste restreinte de variables explicatives (position géographique, régime de vent…) et des paramètres intrinsèques les plus performants possible.
Pour l’hydraulique, nous testons de nouvelles sources de données de débits d’eau aujourd’hui en opendata et en gros volume grâce à l’ouverture de la base HubEau (base de données sur l’eau disponibles en open data, mise en place notamment par le Bureau de Recherche Géologiques et Minières et l’Agence Française pour la Biodiversité). Cette base nécessite d’utiliser des outils big data de stockage (Hive) et de requêtage (Spark) : chaque mois ce sont 12 000 000 points de mesure qui sont ajoutés. Nous testons actuellement sur ces données les méthodes de machine learning pour prévoir la production du jour pour le lendemain ; les résultats sont très encourageants.
Cas d’usage 2 : Le traitement automatique du langage au service de la Programmation journalière
Chaque jour, notre Centre Programmation et Optimisation reçoit des contrats de performance journalière de chaque tranche de production thermique. Une soixantaine de rapports sont à saisir, lire, comprendre, et vérifier par les opérateurs qui doivent assurer la cohérence des informations et statuer sur les aptitudes techniques des tranches pour les horizons J+1 et J+2. Une activité dans laquelle l’intelligence artificielle peut aider l’humain. Un outil IA a été construit afin de :
A. Automatiser la saisie de donnée ;
B. Interpréter les commentaires libres et en déduire si la tranche est apte à réaliser certaines opérations (suivi de charge, service système etc.) ;
C. Détecter les incohérences au sein des données structurées et avec les commentaires, à l’aide des règles métiers prédéfinies ;
D. Proposer aux opérateurs un double rapport avec version initiale et version modifiée (avec les incohérences corrigées ou surlignées en fonction de la confiance dans le diagnostic).
L’outil permet de gagner en temps et en efficacité. Le traitement automatique du langage (TAL) intervient dans la partie ‘interprétation des commentaires’. Il s’agit d’une classification binaire de texte libre avec un corpus de texte très orienté vers la production nucléaire. Dans le cadre de l’amélioration continue, un travail est en cours pour augmenter la performance du modèle TAL.
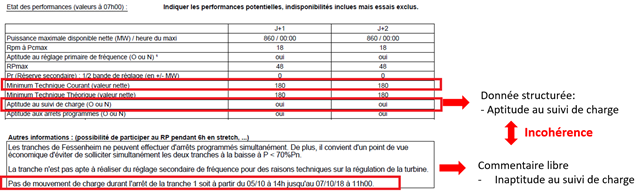
Une démarche en plusieurs étapes que nous nous proposons de décrire ci-dessous :

1. Acquisition des données
Après avoir collecté un nombre suffisant de commentaires, une première étape importante a consisté en l’annotation de chaque commentaire par des experts : 0 pour inaptitude ou 1 pour aptitude. A titre d’exemple :
Commentaire 1 : Pas de mouvement de charge durant l’arrêt de la tranche 1. ➔ label = 0 (0 pour inaptitude)
Commentaire 2 : La tranche est apte au suivi de charge. => label =1 (1 pour aptitude)
2. Prétraitement
Les commentaires sont « nettoyés » pour ne garder que des mots utiles et limiter le nombre de « vocabulaires ». Cette étape a pour but de standardiser le texte afin de faciliter les étapes de vectorisation et classification. Les techniques classiques comprennent :
- Tokenisation qui transforme un texte en une série de mots (tokens) ;
- Suppression des mots les plus fréquents (stop words) ;
- Suppression des ponctuations ;
- Stemming qui réduit un mot dans sa forme de racine ;
- « Lemmatisation », etc.
Illustration pour le commentaire 1 :
Pas de mouvement de charge durant l’arrêt de la tranche 1. ➔ pas mouv charge arrêt tranche
3. Vectorisation : texte ➔ numérique
Les commentaires ainsi prétraités sont ensuite transformés en une matrice avec des techniques de vectorisation. A titre d’illustration, la technique la plus simple est de compter le nombre d’occurrences de mots.
Cette méthode est retenue dans certains cas d’usage mais elle a ses limites : elle ne tient pas compte de l’ordre des mots au sein d’un texte et elle n’intègre pas le sens sémantique du vocabulaire. La méthode N-Gram ou la méthode plongement de mots (Word2Vec) permettent d’améliorer la performance pour notre cas d’usage.
4. Entraînement à l’aide d’un algorithme ML
La matrice avec les labels alloués est utilisée pour entraîner un modèle d’apprentissage supervisé. Des algorithmes à la base des arbres de décision (Gradient Boosting, etc.) ont permis d’obtenir une performance satisfaisante. La technique des réseaux de neurones récurrents a été testée mais elle a une performance moyenne pour plusieurs raisons. D’une part, le nombre de commentaires pour entrainement est très faible par rapport au volume nécessaire pour un apprentissage approfondi, d’autre part, les vocabulaires sont très spécifiques à la production nucléaire et il est donc peu pertinent d’utiliser un modèle pré-entraîné.
5. Mesure de performance et validation du modèle
Différentes méthodes de vectorisation et de classification ont été testées et ont permis de comparer les performances du modèle.
6. Prédiction
Le modèle entraîné, une fois validé, permet de prédire les aptitudes techniques.
Cas d’usage 3 : prévision de disponibilité du parc de production Nucléaire
CONTEXTE
Chaque jour, les responsables du processus opérationnel doivent fournir pour le lendemain un empilement des moyens de production équilibrant au moindre coût la demande prévisionnelle adressée à EDF. Ils utilisent un modèle d’optimisation (tir modèle) qui nécessite une vision très fine de la performance des équipements et notamment de la disponibilité prévisionnelle des moyens de production nucléaire pour le lendemain qui est particulièrement difficile à prévoir lors du retour sur le réseau d’un des 56 réacteurs du parc de production d’EDF suite à des opérations de rechargement de combustible ou de maintenance.
Par le passé, les hypothèses sur le volume disponible étaient prises « à dire d’expert », sur la base du type de maintenance que la centrale nucléaire venait d’effectuer, des difficultés de la tranche à remonter, etc. En 2019, nous avons mis en service un modèle de Machine Learning pour produire ces hypothèses.
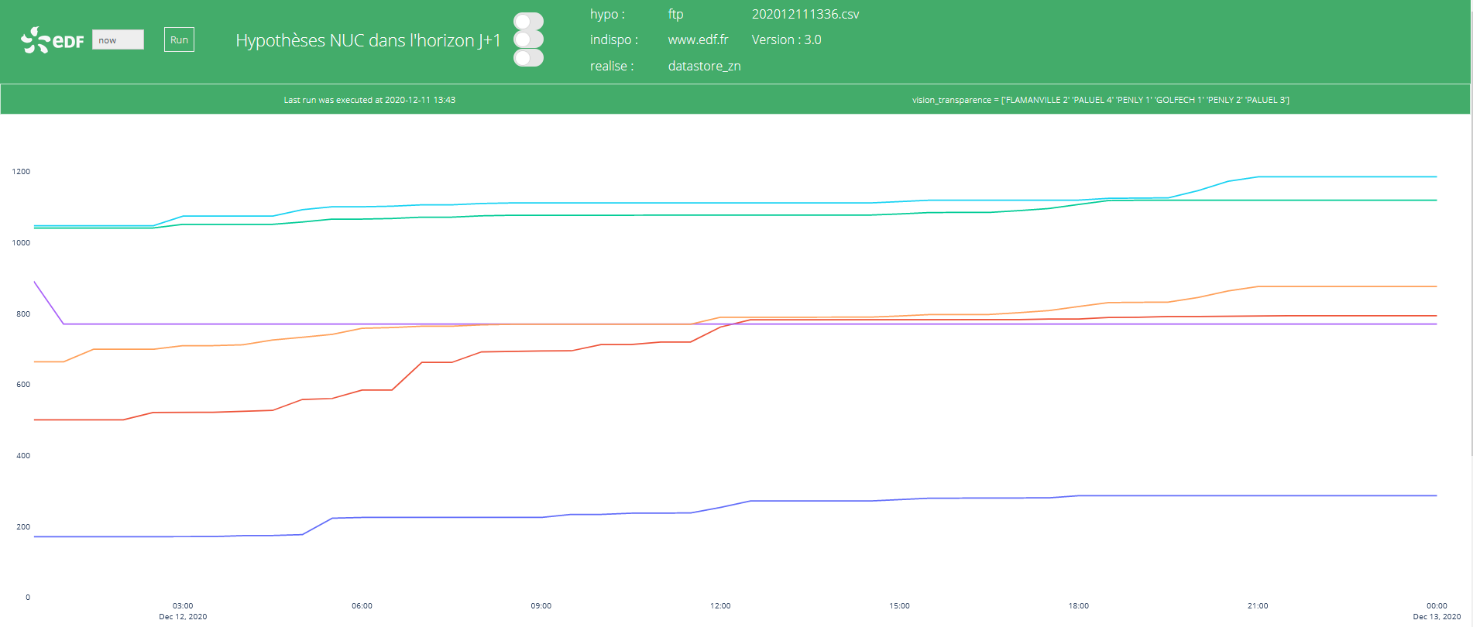
BESOINS
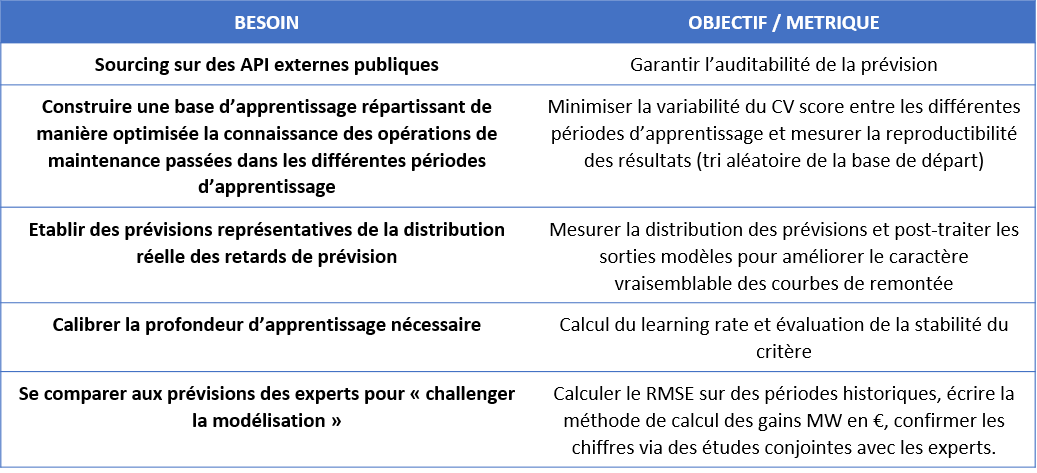
RESULTATS
On observe une variabilité importante dans les résultats obtenus sur le jeu de test. Globalement les scores de RMSE (erreur quadratique moyenne ) sont cependant significativement meilleurs que ceux obtenus via les hypothèses prises par les experts. La variabilité en sortie s’explique notamment par la combinaison des tirages aléatoires dans les variables d’entrée, ainsi que par la présence d’aléas dans certains évènements modélisés.
Représentativité des sorties modèles
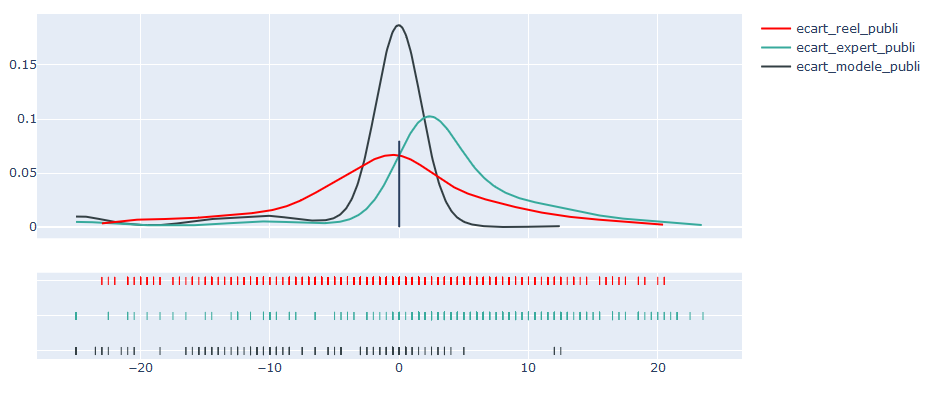
La représentativité des sorties modèles implique le post-traitement des prédictions du modèle. Ce post-traitement permet d’obtenir une sortie qui soit physiquement vraisemblable (continue, strictement croissante). En outre, il vise à établir une vision « centrée » sur la réalité, c’est-à-dire ni pessimiste ni optimiste. La représentation de la distribution permet de s’assurer que les post-traitements n’impactent pas le caractère centré des publications et orientent les actions correctives si ce n’est pas le cas.
Optimisation de la performance
Les résultats ont montré une « consolidation » du gain capté par les experts métiers à hauteur de plusieurs M€/an tout en permettant une meilleure auditabilité des résultats par les autorités de régulation.
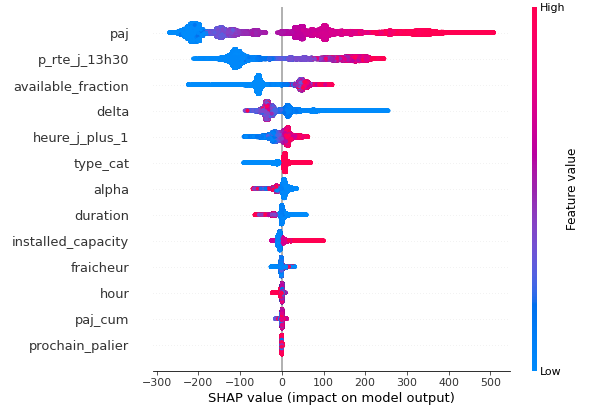
Cette performance est principalement le fruit d’une sélection de variables pertinente obtenue par le biais d’échanges avec les experts. Contrairement à l’attendu, l’étape de tuning des modèles n’est pas celle qui permet d’obtenir l’évolution de la performance la plus significative (retour d’expérience de l’usage des techniques d’auto-ML). Le modèle et sa performance restent liés à la compréhension des variables explicatives et leur influence sur la disponibilité des moyens de production.
En conclusion
La gestion optimisée d’un parc de production de grande dimension dans le marché de l’électricité devient de plus en plus complexe et nécessite d’acquérir et de traiter avec des constantes de temps de plus en plus courtes des volumes de données de plus en plus massifs. Les démarches initiées depuis quelques années à la DOAAT (autour du Machine learning tout particulièrement) sont d’ores et déjà porteuses de valeur, nous travaillons à étendre leur domaine d’utilisation au sein de nos processus en étant particulièrement vigilants à maintenir la proximité entre les spécialistes du data et les futurs utilisateurs.
A partir de 1998,travaille tout particulièrement sur la séparation entre les activités réseau et production du système électrique. A partir des années 2000, dirige plusieurs entités opérationnelles en charge de la gestion de l’équilibre offre-demande du périmètre EDF, actuellement Directeur de la Direction Optimisation Amont Aval, Trading d’EDF.
Sébastien Pelissier : Sébastien a travaillé dans de nombreuses entités d'EDF notamment enRecherche et Développement sur des projets de développement de la mobilité électrique et des parcs éolien en mer. Après un passage de 5 ans dans la filiales d'EDF au Royaume-Uni il a rejoint la DOAAT en 2015. Sébastien pilote désormais un service de valorisation de la données de cette direction dédiée à l'optimisation de l'équilibre offre demande électrique d'EDF SA.
Article très intéressant à plusieurs égards.
D’abord, c’est une grande satisfaction de voir que les ENSAE investissent le champ de l’analyse du nouvel aléa pour l’équilibre O/D du marché de l’électricité. Le parcours de Marc Ribière illustre de manière fort intéressante comment l’aléa économique s’est déplacé du champ de la demande (où les courbes intraday d’eco2mix sont d’une grande régularité) à celui de l’offre, en gagnant en complexité quant à la prévisibilité de cet aléa.
Ensuite, c’est très satisfaisant de voir le producteur chercher des solutions du côté de l’offre, plutôt que d’entendre le discours lénifiant et improductif sur la critique de l’intermittence. Il est clair qu’avoir perdu sa place de 1er de classe au merit-order pousse le producteur à chercher des solutions ailleurs que du coté de la technique et de l’ingénierie. Sur ce terrain, cet article illustre la réelle contribution que les ENSAE peuvent apporter à mieux comprendre l’avenir de l’électricité ENR, pourvu qu’on accepte et mesure l’aléa de la ressource et qu’on sache la mesurer comme un aléa économique.
Je trouve très intéressant également la démarche qui s’intéresse à la prévisibilité du TIR, sans doute une avancée vers un modèle de fourchette de l’électricité ? (ie. une confrontation intraday de carnets d’ordre fins).
Sur le fond, j’ai plusieurs remarques.
Il serait intéressant de clarifier la notion de périmètre, l’article entretient le flou en suggérant qu’EDF resterait plus ou moins responsable de l’ensemble de l’équilibrage. Sans doute un premier chapitre sur les CRM et sur la définition du périmètre d’équilibre serait-il bienvenu, en expliquant qui sont les plus gros contributeurs de l’équilibre, ceux qui ont des obligations réglementaires de contribution à l’équilibrage, comment s’articulent leurs contributions respectives au quotidien sur le réseau, en reposant alors en effet la question de l’intérêt économique du producteur dans cet ensemble eu égard à son propre parc existant.
Un cours rappel des notions de marché de l’électricité serait également bienvenu : dire que c’est un marché particulier où l’équilibre physique s’impose comme contrainte préalable de l’équilibre économique (ce qui pourrait d’ailleurs faire douter de la véracité de ce dernier, nonobstant l’argument idoine des marchés de gros et des interconnexions), dans un contexte de demande inélastique et d’offre de plus en plus volatile en raison de l’émergence des ENR et d’un parc nucléaire non pilotable (j’assume). Le producteur historique se trouve donc confronté à des enjeux multiples de contributeur d’équilibre, de valorisation d’un parc vieillissant non pilotable et de l’émergence d’une ressource ENR à valoriser en tant que propriétaire de telles capacités, mais économiquement contraint par la volatilité globale de la disponibilité de cette ressource renouvelable. Le monopole historique se trouve ainsi « price taker » d’une volatilité externe pour optimiser la valeur de son propre parc, problématique bien connue en finance (et donc déjà solvable).
Le cas n°1 est très riche en données et résultats (êtes vous sûr que l’éolien produise « au fil de l’eau », même si on parle là des modèles… 😉 ). Plus sérieusement, avez-vous envisagé de l’étendre sur des opendata du solaire ? Ce serait passionnant.
La fin du cas n°3 est un peu difficile à suivre, voire absconse. On aimerait une plus grande lisibilité sur la contribution au fonctionnement du carnet d’ordre. Et à tout le moins sur les résultats de la variable de sortie modélisée. J’ai du mal à comprendre que le volume de nucléaire disponible soit difficile à prévoir, compte tenu de la lenteur des temps de réponse et de montée/descente en charge. Le graphique est illisible.
Le cas n°2 est clair et didactique, bien structuré, mais on aimerait en apprendre plus à la fin. Une section 6 un peu plus développée, et sans doute une section 7 sur les applications réalisées ou envisagées/envisageables.
Bravo en tout cas,
Amicalement
a. (94)