
De la « hype » et des maths
Intelligence artificielle, réseaux de neurones, deep fake, apprentissage profond, reportages sur Netflix, cas d’usages populaires parmi lesquels le jeu de go ou des tableaux générés à la manière de Rembrandt : que ce soit sur les appellations, sur l’occupation médiatique, ou sur les thèmes abordés… S’il existait, le brand manager du machine learning (ML) moderne donnerait des conférences à des foules conquises car il a réussi le tour de force de faire parler de maths à peu près tout le monde. On assiste ainsi à des débats souvent idéologiques et pas toujours très bien renseignés sur l’Intelligence Artificielle (IA). Il n’est pas impossible que ce phénomène de hype ait pu provoquer un retard à l’allumage d’une partie de la communauté scientifique sur le mode du “c’est trop à la mode pour être sérieux”. Il faut dire que cette révolution mathématique venait non pas des mathématiques ni de la physique mais de l’informatique, qui plus est sur des problèmes réputés impossibles et de manière un peu outrancière, le tout sans autre preuve de convergence que des preuves empiriques. Cinq ans en arrière, on pouvait donc entendre “Ce ne peut pas vraiment être sérieux“, “C’est du vent, ça ne marche pas vraiment”. Je renvoie vers les excellents cours du collège de France de Stéphane Mallat qui explique bien les raisons de l’incrédulité des débuts : sur certains problèmes, ce ne devait pas marcher.
Et pourtant ça marche ! Les démonstrations empiriques ont rapidement converti les incrédules et montraient que c’était très sérieux. Car une fois passée l’euphorie de la reconnaissance d’images de chats, beaucoup de problèmes historiques sont tombés; problèmes très visuels (jeu de go, deep fake) ou plus matheux (résolution numérique d’Equations aux Dérivées Partielles (EDP) en grande dimension, résolution de problèmes de contrôles, problèmes d’optimisation combinatoire). Des papiers sobrement intitulés “Overcoming the curse of dimensionality (…)” (Jentzen et. al (2017)) défrayaient la chronique et à juste titre. Soudain, un stagiaire muni d’un PC pouvait résoudre une EDP semi-linéaire en dimension 100 en une après-midi de Python quand une nuit sur cluster, du C++ et un expert étaient jusqu’alors nécessaires pour attaquer la dimension 5. Car non contentes d’être diablement efficaces, ces techniques sont rendues facilement accessibles via des librairies open source de très grande qualité et via des environnements d’exécution déportés fournis par les GAFAM (enfin surtout les GFA).
On vit actuellement une période assez extraordinaire qui voit travailler sur le même sujet plusieurs branches des mathématiques (analystes, géomètres ou statisticiens) pour le côté théorique, à peu près toutes les industries et quasiment tous les domaines scientifiques (astrophysique, chimie, archéologie, biologie ou médecine). Dans tout cela, la finance n’a pas été la dernière à réfléchir à des utilisations. D’habitude, on a un clou et on cherche le marteau pour l’enfoncer, ici c’était l’inverse : quel clou ce marteau allait-il bien pouvoir enfoncer ?
IA en finance : prédiction de prix, stratégies de gestion et régulation
Les méthodes modernes de Machine Learning (ML) utilisent des algorithmes d’optimisation faisant intervenir un grand nombre de données et plutôt en grande dimension. Alors, que ces techniques révolutionnent-elles? Premièrement, exit les hypothèses de linéarité; aujourd’hui, il est très simple d’approcher des fonctions non linéaires. D’apparence, cela donne un gros coup de vieux à nos bonnes vieilles régressions linéaires. Deuxièmement, ces méthodes semblent peu sensibles à la dimension (la classification d’images est un problème en dimension excessivement grande (supérieure au million)). Troisièmement, on peut aujourd’hui traiter des données textuelles ou des images de manière très simple et last but not least, les méthodes d’optimisation qui leur sont associées permettent a priori de traiter des problèmes non convexes. Tout cela, couplé à la puissance de calcul et à la facilité d’utilisation de ces techniques grâce à l’open source, explique les succès tonitruants du ML, succès qui ont notamment commencé par de la reconnaissance d’images.
Alors justement, puisqu’on arrivait à distinguer une image de chat d’une image de chien avec un taux de réussite de 99 %, le tout puissant Machine Learning pouvait bien reconnaître une action appelée à prendre de la valeur d’une action qui devait en perdre. Rapidement, on a ainsi vu passer des articles promettant de prévoir des cours d’actions avec un taux de confiance très élevé et sur des marchés très liquides. Malheureusement, la mise en pratique de ces travaux sur des séries temporelles de prix n’a pas confirmé les promesses. En tout cas, pas avec les données accessibles au commun des mortels.
Gardons les pieds sur terre. Ces technologies révolutionnent beaucoup de choses, mais ce qui était interdit d’après les lois les plus basiques de l’économie doit le rester. Dit autrement, il n’y a sur la durée toujours pas de free lunch, ni d‘arbitrage. Le cas contraire serait une faille dont la disponibilité des données et des algorithmes rendrait la durée extrêmement courte. A moins de faire du HFT[1], d’utiliser temporairement des données que les autres n’ont pas encore intégrées, on ne peut espérer aucun gain gratuit systématique et certain. Des travaux plus nuancés (Gu et Kelly (2020)) tendent néanmoins à montrer un avantage relatif mais non décisif des réseaux de neurones sur les prévisions de prix par rapport aux régressions linéaires usuelles. Encore faut-il bien calibrer les hyper paramètres. Et pour ce faire, deux possibilités : l’agrégation d’experts (Keywan et al. (2019)) et l’autoML (He et al. (2020)). Dans le premier cas, on mélange judicieusement plusieurs algorithmes, dans le second cas, on utilise des méthodes d’optimisation pour trouver les meilleurs paramètres et les meilleures architectures.
On ne peut certes pas profiter d’un gain certain avec des données de prix très accessibles mais peut-être qu’en scrutant les fils Twitter et en les intégrant à nos algorithmes de prévision de prix, on pourrait avoir un avantage (Oliviera et al. 2017)? En réalité, le temps que met un tweet d’Elon Musk à se répercuter sur les indices concernés est epsilonesque. Et si l’on payait une fortune des photos satellites de bateaux quittant les ports méthaniers pour prévoir s’ils rentraient au port ou s’ils allaient chercher des barils? Là aussi, tout le monde a fini par le faire. On assiste ainsi à une course à la donnée dite alternative de plus en plus exotique, de plus en plus protégée et surtout de plus en plus chère (le vendeur de tamis s’enrichit souvent plus que le chercheur d’or). L’enjeu dans ce cas d’application est bien la donnée et non la partie algorithmique. Alors, peut-être qu’en utilisant des données dont personne d’autre ne disposera jamais, on pourrait avoir un avantage définitif ? Et là, nul besoin d’IA, on appelle cela le délit d’initiés.
Outre la prévision de prix, la capacité à utiliser des données de nature hétérogène peut être utilisée pour construire des dashboards permettant à l’opérateur de disposer d’une synthèse de ce qu’il se passe sur internet, sur les réseaux sociaux ainsi que sur les marchés qui le concernent. L’IA ici ne décide pas à la place de l’opérateur mais a bien un rôle d’assistant.
Une autre famille d’applications concerne la reproduction d’outils de calculs car on doit bien le confesser : la finance est une grosse consommatrice de temps de calcul. Des montants non négligeables ont été et sont encore dépensés pour rendre plus rapides des codes de calculs, pour les optimiser, les paralléliser, les faire tourner sur des cartes graphiques, parfois en pure perte. Seulement aujourd’hui, quel intérêt a-t-on à recruter un développeur expérimenté pour gagner un hypothétique 30 % en temps de calcul sur un outil de pricing lorsque l’on peut lancer l’outil des millions de fois et reproduire son comportement par une IA qui, une fois entraînée, se lance en quelques millisecondes, tout en fournissant en plus des dérivées partielles (et donc des sensibilités) jusqu’alors difficilement accessibles ?
L’exemple de la reproduction d’outil est un cas d’application qui s’appuie uniquement sur des données synthétiques. Il est ainsi erroné de réduire le Machine Learning à la data science car on peut aussi profiter du ML si on a très peu, voire pas de données du tout; surtout en finance car dans ce domaine on sait très bien simuler : simuler des prix, simuler des valeurs de portefeuilles, on y travaille depuis des dizaines d’années. Ce savoir-faire sur les simulateurs et les modèles est heureusement utilisé dans le calcul de stratégies optimales par réseaux de neurones (Buehler et al. (2019)). Dans ce cas, on se donne un critère ainsi qu’un simulateur Monte Carlo, et un algorithme de renforcement nous propose une stratégie optimale. Ce cadre cible illustré sur la Figure 1 change beaucoup de choses et pose plusieurs questions.
Avant tout et comme dit plus haut, même si c’est mieux, le critère n’est plus forcément convexe. Nous sommes ainsi libres de le changer. Par exemple pour la couverture de risques, certes la réduction de variance du portefeuille couvert est un problème qui possède de bonnes propriétés mathématiques mais est-ce bien le critère qu’un gestionnaire de risques doit minimiser ? Dit autrement, un gestionnaire de risques a-t-il vraiment envie de pénaliser autant ses pertes que ses gains? L’IA permet justement dans ce cas d’utiliser d’un critère asymétrique pénalisant plus les pertes que les gains (Fécamp et al. (2021)). Maintenant qu’on peut numériquement se le permettre, des réflexions profondes sont ainsi menées pour savoir quel critère est le plus approprié et pour quelle entité (critère en quantile, critère global ou critère local). D’autant que ces méthodes sont plutôt flexibles et on y intègre facilement des réalités de marchés telles que les contraintes de liquidité, les coûts de transactions ou encore le market impact. De plus, la stratégie en sortie peut dépendre de cent facteurs de risques sans que cela ne pose de problèmes alors que jusqu’alors, sur les cas complexes que l’on regarde aujourd’hui, la dimension 4 était l’Himalaya (comprenez une nuit de calcul sur un Calculateur Haute Performance (HPC)) et la dimension 5 était inatteignable.
Pour alimenter les méthodes de renforcement, l’industrie bancaire (au moins autant que les médias) regarde de près les méthodes génératives. Après tout, si l’on sait générer des Rembrandt (voir Next Rembrandt (2021)) on doit savoir faire de même pour des séries temporelles. L’application des méthodes génératives aux séries temporelles n’est malheureusement pas aussi directe que l’on aurait pu espérer mais des solutions émergent (Yoon et al. (2019), Remlinger et al. (2021)). Encore mieux, on arrive à contourner une éventuelle faible disponibilité de la donnée en utilisant le transfer learning qui permet de mélanger des données issues d’un simulateur à des données réelles lors de la phase d’apprentissage sur le mode : si on a appris à jouer de l’orgue, on aura besoin de moins de temps pour apprendre le piano que si on n’a rien appris du tout.
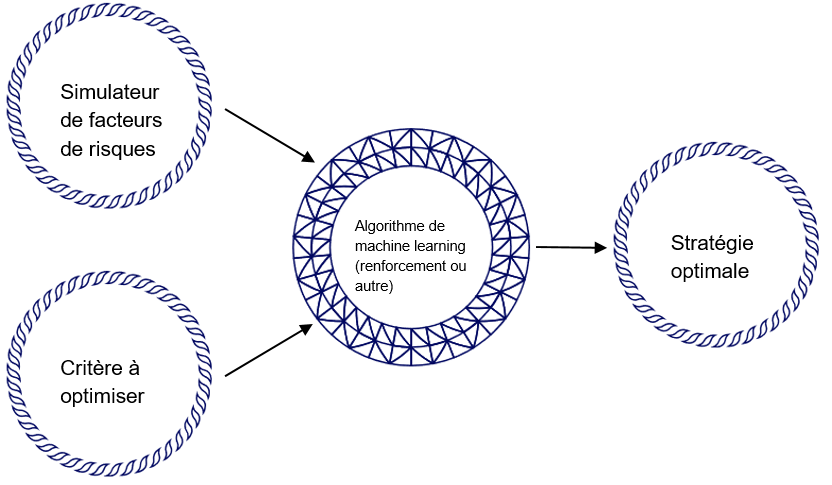
Figure 1. Calcul de stratégie optimale.
Vient la question de la boîte noire. Si l’on revient un peu en arrière, l’on passait beaucoup de temps en amont des algorithmes pour les mettre au point, écrire leur cahier des charges, les développer, optimiser les codes et une fois ces codes prêts on les mettait relativement rapidement en opérationnel. Dans les précédents cas d’usages, une grande partie du temps de design et du temps de développement des algorithmes a été déplacée vers la phase de tests côté expert métier et c’est tant mieux. En finance, un data scientist seul ne suffit pas car sans les expérimentations menées par l’expert métier, pas d’IA. La flexibilité et la rapidité des méthodes de ML aident l’expert métier à affiner sa compréhension des mécanismes de marchés, à contredire ou à confirmer ses intuitions et à mieux modéliser son besoin. L’IA ne remplace alors pas l’expert mais au contraire elle consolide sa connaissance. Cet échange vertueux qui se met en place dans les bons cas est en outre aidé par des outils d’interprétabilité (Rudin (2020)).
Cela est bien beau pour le côté opérationnel, mais qu’en est-t-il du régulateur ? Comment faire accepter à un régulateur que nos décisions viennent d’un algorithme qui a la réputation d’être une boîte noire? Régulateur dont la méfiance doit, qui plus est, être attisée par des mini-krachs provoqués par des algorithmes de trading automatiques. Mini-krachs que l’uniformisation des méthodes de ML et autres HoaxCrash ne rendront que plus fréquents. Un peu sur le même thème, on peut renchérir sur une expression tout aussi bien trouvée que celles mentionnées au début : les attaques adversariales qui, sur le papier, pourraient être utilisées par un investisseur de marché au parfum de la stratégie de son concurrent pour le mettre à mal (Lin et al. (2017), Goldblum et al. (2020)).
La question de la confiance ne peut pas nous empêcher d’utiliser le ML. Après tout, les régulateurs eux-mêmes utilisent l’IA pour monitorer les actions frauduleuses. Plus généralement, l’explicabilité et l’interprétabilité sont des champs de recherche assez féconds, stimulés notamment par les acteurs de l’automobile, de l’aéronautique ou encore de la médecine pour qui l’acceptabilité est très dure à acquérir (Gilpin et al. (2018)).
Très récemment, l’Union Européenne (UE) a publié une note sur l’IA (Commission Européenne (2021)) dans laquelle une liste de secteurs à haut risques est dressée. Pour ceux qui font partie de cette liste (et c’est le cas du milieu bancaire à travers notamment le risque de crédit), l’UE conseille de mettre place des “systèmes adéquats d’évaluation et d’atténuation des risques”. Nouveaux risques, nouvelles stratégies pour les atténuer : côté finance, les institutions et les régulateurs voient là s’ouvrir un nouveau champ de questionnements dont vont immanquablement découler de nouvelles innovations.
Mots-clés : finance – deep hedging – machine learning – méthodes génératives – prévision de prix
Cet article a été initialement publié le 3 mai 2021.
[1] Trading à haute fréquence
Bibliographie
Buehler, H., Gonon, L., Teichmann, J., & Wood, B. (2019). Deep hedging. Quantitative Finance, 19(8), 1271-1291.
Commission Européenne (2021), Une Europe adaptée à l’ère du numérique: La Commission propose de nouvelles règles et actions en faveur de l’excellence et de la confiance dans l’intelligence artificielle.
Fécamp, S., Mikael, J., Warin, X (2020). Deep learning for discrete-time hedging in incomplete markets. Journal of Computational Finance
Gilpin, Leilani H., Bau, David, Yuan, Ben Z., et al. Explaining explanations: An overview of interpretability of machine learning in : 2018 IEEE 5th International Conference on data science and advanced analytics (DSAA). IEEE, 2018. p. 80-89.
Goldblum, M., Schwarzschild, A., Cohen, N., Balch, T., Patel, A. B., & Goldstein, T. (2020). Adversarial Attacks on Machine Learning Systems for High-Frequency Trading. arXiv preprint arXiv:2002.09565.
Gu, S., Kelly, B., & Xiu, D. (2020). Empirical asset pricing via machine learning. The Review of Financial Studies, 33(5), 2223-2273.
Han, Jiequn and Jentzen, Arnulf and Weinan, E, 2017 Overcoming the curse of dimensionality: Solving high-dimensional partial differential equations using deep learning
He, X., Zhao, K., & Chu, X. (2021). AutoML: A Survey of the State-of-the-Art. Knowledge-Based Systems, 212, 106622.
Keywan C. R. & Robert C. J (2019) Machine Learning for Stock Selection, Financial Analysts Journal, 75:3, 70-88, DOI:10.1080/0015198X.2019.1596678
Lin, Y. C., Hong, Z. W., Liao, Y. H., Shih, M. L., Liu, M. Y., & Sun, M. (2017). Tactics of adversarial attack on deep reinforcement learning agents. arXiv preprint arXiv:1703.06748.
Mallat, S (2017- 2018) L’apprentissage par réseaux de neurones profonds, Cours du collège de France – Chaire Sciences des données
Mallat, S (2018- 2019) L’apprentissage par réseaux de neurones profonds Cours du collège de France – Chaire Sciences des données
Next Rembrandt (Avril 2021) https://www.nextrembrandt.com/
Oliveira, N., Cortez, P., & Areal, N. (2017). The impact of microblogging data for stock market prediction: Using Twitter to predict returns, volatility, trading volume and survey sentiment indices. Expert Systems with Applications, 73, 125-144.
Remlinger, C, Mikael, J., & Elie, R. Conditional Versus Adversarial Euler-based Generators For Time Series. arXiv preprint arXiv:2102.05313, 2021.
Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat Mach Intell 1, 206–215 (2019).
Yoon, J., Jarrett, D. & Van Der Schaar, M. Time-series generative adversarial networks. Neurips 2019.

Commentaires récents